Una página web es un archivo de texto que, en vez de en español, está escrito en HTML. A diferencia de otros lenguajes, este no se utiliza para programar algoritmos (desarrollo de código tradicional) sino con el fin de estructurar el contenido de una página web.Por lo tanto, HTML no es un lenguaje de programación, sino de marcas, motivo por lo que, en vez de variables, funciones, clases o estructuras de control, utiliza etiquetas (marcas) que establecen el papel que juega cada uno de los elementos que conforman la página.
2.1 ELEMENTOS HTML
Los elementos HTML son las piezas con las que se construyen las páginas web.
Aunque a lo largo de esta obra se emplearán los términos elemento y etiqueta de forma indistinta, en realidad el primero abarca al segundo, ya que un elemento se compone de:
Una etiqueta de apertura con cero o más atributos.
El contenido afectado, que puede ser un texto u otras etiquetas.
Una etiqueta de cierre.
Por lo tanto, y con carácter general, un elemento HTML tiene el siguiente formato:
Aunque este es el caso general, hay elementos que no tienen atributos, otros que solo requieren una etiqueta (la de inicio) e, incluso, algunos no tienen contenido. Los nombres de las etiquetas pueden escribirse tanto en mayúscula como en minúscula. Sin embargo, el W3C (consorcio internacional dedicado a la definición de normas y directrices web) recomienda el uso de minúsculas.
Cuando una etiqueta lleva atributos, estos son los encargados de suministrar la información precisa para realizar su función. Por ejemplo, una etiqueta que muestre una imagen requiere un atributo que contenga la ruta de acceso donde está almacenada, la etiqueta de un hipervínculo necesita la dirección de la página a la que se accede, etc.
Observe que los atributos se separan mediante espacios (no con comas) y que sus valores van siempre entre comillas. Si recuerda, en el capítulo de introducción se utilizó un código HTML de ejemplo en el que se empleaba la etiqueta <a> para crear un hipervínculo mediante el que se podía acceder a la página de búsqueda de Google, cuyo URL se añadió mediante el atributo href:
<a href="http://www.google.es" class="a">Este es un enlace al buscador de Google</a>
Si quiere conocer la lista completa de los atributos globales (aquellos que se pueden usar en cualquier etiqueta) visite la página https://developer.mozilla.org/es/docs/Web/HTML/Global_attributes
Las etiquetas imprescindibles en cualquier página web son las siguientes:
Aunque la primera línea tenga el aspecto de una etiqueta, en realidad es una directiva que indica al navegador que este documento está escrito en HTML5 (última versión de este lenguaje). Por ese motivo, esta línea siempre deberá situarse al principio del archivo:
<!DOCTYPE html>
A lo largo de esta obra, para referirse al código HTML de una página web también se utilizará el término documento.
El siguiente par de etiquetas son las que realmente contienen el código HTML de la página y conforman el elemento raíz del documento, ya que agrupa a todos los demás:
<html>
...
</html>
Como se ha comentado al inicio de esta sección, la función principal de HTML es estructurar el contenido de la página. Para ello, los elementos se anidan unos dentro de otros formando una jerarquía cuya raíz es la etiqueta <html> (representa la página web), debajo de la que se encuentra el cuerpo y la cabecera (etiquetas <head> y <body>):
Aunque más adelante se describirán las estructuras jerárquicas, la que forman el cuerpo y la cabecera de una página se puede representar gráficamente así:
En la cabecera está la información general de la página, como los metadatos y las referencias a los archivos externos donde se almacenan las hojas de estilo CSS, el código JavaScript, etc.
<head>
...
</head>
Los metadatos reciben este nombre porque son datos que describen otros datos. Aunque no sea información visible, es muy importante porque la utilizan los buscadores para localizar las páginas que mejor se adapten al contenido solicitado por un usuario.
Por último, el cuerpo del documento contiene los elementos visibles de la página web:
<body>
...
</body>
Ahora que ya conoce las etiquetas que no pueden faltar en ninguna página web, en la siguiente sección desarrollará la primera y más sencilla de todas. La lista de todos los elementos HTML los puede encontrar en https://developer.mozilla.org/es/docs/Web/HTML/Element y en https://www.w3schools.com/tags.
2.2 SU PRIMERA PÁGINA WEB
Una vez conocida la estructura básica de una página web y las etiquetas que intervienen, ya está en condiciones de crear la primera. Por lo tanto, ha llegado la hora de ponerse manos a la obra y empezar a practicar lo aprendido. Pero ¿es necesario algún tipo de entorno de desarrollo para ello? No, ya que una página web es un documento de texto, por lo que podrá editarse con cualquier procesador de texto, por muy sencillo que este sea (por ejemplo, el bloc de notas de Windows o TextEdit si utiliza Mac).
En Windows, para abrir el bloc de notas solo tiene que escribir su nombre en el campo de búsqueda situado en la parte inferior izquierda del escritorio y, luego, pulsar sobre él.
Si va a trabajar de forma habitual con archivos HTML, le recomiendo usar Visual Estudio Code. Aunque no es un editor específico de HTML, una vez que detecta ese lenguaje le ofrece infinidad de facilidades que le facilitarán la escritura del código, como la función de autocompletar, el cierre automático de etiquetas, menús contextuales de ayuda sobre la sintaxis o enlaces a la web https://developer.mozilla.org/ en la que se ofrece toda la información que necesite de un elemento determinado. Puede descargarlo desde https://code.visualstudio.com/download.
Una vez abierto el editor, escriba el siguiente código:
<!DOCTYPE html>
<!-- esta es mi primera página web -->
<html>
<head>
</head>
<body>
hola mundo
</body>
</html>
En dicho código, la única línea cuya sintaxis no se ha explicado es:
<!-- esta es mi primera página web -->
Se trata de un comentario. Como en cualquier otro lenguaje de programación, en HTML también se pueden añadir comentarios que ayuden a entender el código. Se trata de líneas de texto que ignora el navegador, ya que van destinadas al desarrollador de la página web. Se utilizan en labores de mantenimiento, sobre todo cuando se trata de páginas complejas. Los comentarios también son útiles durante la fase de depuración de errores, ya que permiten ocultar líneas de código que pueden ser sospechosas de provocarlos.
Una vez finalizado el documento HTML, guárdelo con el nombre “hola-mundo.html”. Si quiere seguir la estructura de carpetas del material descargable del libro, el código de este y los sucesivos ejercicios se encuentra dentro de la carpeta “Practicas”, agrupados en subcarpetas por capítulos (“Capitulo1”, “Capitulo2”, ...). Por lo tanto, el correspondiente a esta primera página web estaría en:
/Practicas
/Capitulo2 hola-mundo.html
Es importante que su extensión sea “.html”, ya que es la correspondiente a los archivos que contienen páginas web. De esta forma, podrá abrirlos desde un navegador. También es importante que, al guardar el archivo, en el campo “Codificación” elija “UTF-8”. Se trata de un formato de codificación estándar de caracteres que permite el almacenamiento, la transmisión y, muy especialmente, la correcta visualización de aquellos específicos de cada idioma, en el caso del español, los acentos y la letra ‘ñ’.
Como puede observar en la imagen anterior, he situado la carpeta “Practicas” (obtenida el material descargable) debajo de otra llamada “HTML”, en la que tengo todo lo relacionado con este lenguaje. Naturalmente, usted puede ponerla donde quiera.
Ahora, acceda a la carpeta donde guardó el archivo y pulse sobre él con el botón derecho del ratón. En el menú contextual que aparece, seleccione la opción “Abrir con” y, finalmente, “Google Chrome”. Aunque en todas las prácticas se haga referencia a Google Chrome, puede utilizar cualquier otro navegador. Si fuera el configurado por defecto en su ordenador, solo tendría que pulsar dos veces seguidas con el botón izquierdo del ratón sobre el documento HTML (igual que se hace con los archivos de cualquier otra aplicación).
Una ruta absoluta es aquella que especifica la ubicación de un archivo desde el directorio raíz, en este caso, el disco duro (“C:/”). Si quisiera ver cualquier otra página web solo tendría que escribirla en dicha barra de direcciones.
2.3 ETIQUETAS BÁSICAS DE LA CABECERA
Cómo sabe, un documento HTML se estructura en una cabecera y un cuerpo. En esta sección estudiará las etiquetas más comunes de la cabecera (las del cuerpo forman parte de una sección posterior). Son las que permiten mostrar el título y el icono de la página en la pestaña del navegador, definir las reglas de estilo con las que se determina su apariencia, añadir metainformación útil que facilite su localización por parte de los buscadores o importar todo tipo de recursos externos.
Las etiquetas que usará con más frecuencia en la cabecera de un documento HTML son las siguientes:
<title>: Establece el título del documento.
<link>: Importa recursos externos, es decir, aquellos que no están incluidos en el propio documento HTML. Se usa para cargar código JavaScript, hojas de estilo y, como pronto descubrirá, imágenes como la del pequeño icono que aparece al lado del título en la pestaña del navegador.
<meta>: Si en la cabecera es donde se colocan los metadatos de una página web, esta etiqueta es la que mejor representa dicha definición, ya que normalmente se emplea para identificar al autor, dar un breve resumen de lo que trata la página, añadir las palabras clave que mejor representen la información contenida (aquellas que introducirían en un buscador las personas interesadas en ella), identificar el juego de caracteres manejado, etc.
<style>: Agrupa las reglas de estilo con las que se determina el aspecto de los elementos mostrados en pantalla, por ejemplo, el color o el tamaño del texto de un párrafo. Estas reglas, que se escriben en lenguaje CSS, también son las responsables de la distribución de estos elementos en la página según un diseño o una composición gráfica determinada.
Un juego de caracteres especifica la forma en la que un ordenador los representa internamente. Aunque existen distintos estándares, el W3C recomienda el formato de codificación de caracteres Unicode UTF-8.
A continuación se describirá cada una de estas etiquetas, a excepción de <style>, cuyo estudio se llevará a cabo en el próximo capítulo.
2.3.1 Metadatos
Un metadato es un dato que describe a otro dato. En el contexto de las páginas web, los metadatos son información sobre esta, como el autor o el tema del que trata, las palabras clave que mejor representan su contenido o el juego de caracteres empleado. Los metadatos de un documento HTML se expresan en su cabecera mediante la etiqueta <meta>. Al igual que la etiqueta <link>, esta requiere de atributos que proporcionen información adicional. Uno de ellos es charset, con el que se establece el juego de caracteres empleado, imprescindible para que el navegador muestre correctamente la letra ‘ñ’ o los acentos. El que utilizará será UTF-8, por lo que la línea de código que deberá añadir a la cabecera de todos sus documentos será:
<meta charset="UTF-8">
Observe que esta etiqueta no requiere la correspondiente de cierre.
Para que alguien encuentre su página debe proporcionar la máxima información posible a los buscadores. A tal fin, la etiqueta <meta> se usa con la combinación de atributos name y content. El primero indica de qué trata la información que se va a dar en el segundo. Los valores de la propiedad name más utilizados son:
“author”: Autor de la página.
“description”: Breve resumen de su contenido. [cite: 128, 129]
“keywords”: Palabras clave que alguien escribiría en un buscador para encontrarla.
El valor de la propiedad content puede ser cualquier texto. El valor de la propiedad name también podría ser cualquier texto, por ejemplo, “autor” (escrito en castellano) u otro inventado, como “bibliografía”. Sin embargo, se recomienda encarecidamente valerse de términos muy conocidos y en inglés (como los de la lista anterior). A modo de ejemplo, si introdujera las siguientes etiquetas en la cabecera de una página web, informaría a los buscadores de que yo soy el autor (así, sería posible encontrar esta página a partir de mi nombre), junto con las palabras clave que podría escribir alguien interesado en un libro sobre HTML:
Aunque la página web no sufrirá ningún cambio de aspecto, los buscadores dispondrán de información muy valiosa que ayudará a localizarla a todos aquellos interesados en algún libro que yo hubiera escrito sobre HTML.
2.3.2 Título del documento
El título del documento sirve para identificar una página web, ya que se muestra en la pestaña del navegador. Se establece con la etiqueta <title>, tal como se ha hecho en la siguiente línea de código:
<title>Mi primera página web</title>
Además, es el texto con el que se guarda la página cuando se agrega a la lista de favoritos del navegador. Los motores de búsqueda utilizan el título para decidir el grado de coincidencia entre su contenido y lo que busca un usuario.
Incorpore la etiqueta anterior a la cabecera del código de su primera página, que quedaría así:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Mi primera página web</title>
</head>
<body>
Hola Mundo
</body>
</html>
Refresque la página o cárguela de nuevo en el navegador. Como puede observar, ahora en la pestaña no aparece el nombre del archivo donde está almacenada sino el título que le acaba de dar.
Hay tres formas distintas de refrescar el contenido de una página web:
Pulsar con el ratón en la barra de direcciones y luego la tecla de retorno de carro.
Presionar la tecla F5.
Pulsar sobre el botón.
2.3.3 Recursos externos
Los recursos externos son archivos de diversa naturaleza (generalmente, imágenes, hojas de estilo o código JavaScript) necesarios para el correcto funcionamiento de una página web. Para incorporarlos a esta, HTML proporciona la etiqueta <link>, que deberá usarse junto con una serie de atributos que determinen su ruta de acceso, la naturaleza de su contenido y el formato en el que está almacenado. Con el fin de mostrar la forma de utilizar esta etiqueta, la empleará para mostrar un icono (favicon) al lado del título en la pestaña del navegador.
La manera de importar el archivo que contiene la imagen de un favicon en una página web es asignar su ruta de acceso al atributo href de la etiqueta <link>. Pero ¿cómo se especifica una ruta? De forma absoluta, tal como aparecía en la barra de direcciones del navegador al abrir el documento HTML de su primera página web, o de forma relativa, a partir de la carpeta (directorio) en la que se encuentra la página web.
Para explicar cómo se escribe una ruta de acceso relativa (forma recomendada), se analizarán tres escenarios:
El archivo se encuentra en la misma carpeta que la página web.
El archivo se encuentra en una carpeta creada a partir de la que contiene la página web.
El archivo se encuentra en una carpeta creada a partir de otra anterior a la que contiene la página web.
En el primer escenario, imagine que la página web “hola-mundo.html” se encuentra en la carpeta “Capitulo2” dentro de otra llamada “Practicas”. Si el archivo que contiene el icono fuera “mi_favicon.ico” y estuviera situado en la misma carpeta que la página web, la estructura de directorios resultante se podría representar de la siguiente manera:
En este caso, como la página y el recurso externo están en la misma carpeta, la ruta relativa de acceso a dicho archivo sería:
"./mi_favicon.ico"
El punto (‘.’) de la ruta representa la carpeta donde se encuentra la página web. Aunque los caracteres ‘./’ son opcionales, se recomienda utilizarlos.
Ahora, imagine un segundo escenario en el que el favicon no está en la misma carpeta que la página web, sino en otra llamada “Imagenes” creada como subcarpeta dentro de “Capitulo2”, tal como se muestra a continuación:
En ese caso, la ruta de acceso a dicho archivo sería:
"./Imagenes/mi_favicon.ico"
Por último, imagine un tercer escenario en el que la carpeta “Imagenes”, donde se encuentra el favicon, no se ha creado como una subcarpeta de “Capitulo2”, sino dentro de “Practicas”:
Los dos puntos de la ruta (‘..’) representan el directorio padre (“Practicas”), aquel dentro del que se ha creado “Imagenes” como subcarpeta. Puesto que esta es la estructura de directorios del contenido descargable del libro, será la ruta utilizada en el ejercicio desarrollado en esta sección. Siguiendo este razonamiento de forma recursiva, se podría especificar la ruta de acceso relativa de cualquier archivo situado en cualquier carpeta creada en la estructura de directorios del ordenador.
Se preguntará si el hecho de que la carpeta “Imagenes” no lleve acento es un error. No se ha puesto porque los directorios que forman parte de una ruta no pueden llevarlos. Por otra parte, en las rutas de acceso no se distingue entre mayúsculas y minúsculas. Por lo tanto, el nombre de la carpeta “imagenes” sería el mismo que “Imagenes”. Los nombres de archivos o directorios no pueden llevar caracteres especiales como acentos o la letra ‘ñ’.
Solo con asignar la ruta de acceso del favicon al atributo href de la etiqueta <link> no es suficiente para incorporar esta pequeña imagen a la página. Tal como se indicó al principio de la sección, esta etiqueta sirve para integrar recursos externos en el propio documento HTML, que no tiene por qué ser necesariamente un favicon, sino una hoja de estilos, código JavaScript, etc. Por ese motivo, es necesario expresar de forma explícita el tipo de recurso del que se trata, en este caso un icono. Para ello, deberá utilizar el atributo rel, al que tendrá que asignar el valor icon. Cómo estudiará en una sección posterior, cuando el recurso importado sea una hoja de estilo, el valor de esta propiedad será stylesheet.
Por último, para cargar un recurso externo en la página también es necesario especificar el formato del archivo (la extensión del archivo no es indicativo) con la propiedad type. En este caso concreto, su valor es “image/x-icon”.
El valor del atributo type debe ser uno de los establecidos en el estándar MIME (Multipurpose Internet Mail Extensions, extensiones multipropósito de correo de Internet), que clasifica la naturaleza y el formato de los documentos que se intercambian por Internet. Esta información la utilizará el navegador para visualizar o reproducir los archivos correctamente. Aunque no se pretende describir este estándar, observe que su formato es: “tipo/subtipo”. Por eso, si el formato de una imagen fuera jpg, su tipo MIME sería image/jpg. Y si en vez de una imagen fuera un texto normal o HTML, este sería text/plain y text/html, respectivamente. Algo similar sucedería con los archivos de sonido o vídeo.
En consecuencia, la etiqueta <link> que deberá utilizar para cargar y mostrar la imagen contenida en el archivo “favicon.ico” (almacenado en la carpeta “Imágenes”) al lado del título, es la siguiente:
Añada dicha etiqueta al código de la cabecera de su primera página web, que quedaría así:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Mi primera página web</title>
<link rel="icon" type="image/x-icon" href="../Imagenes/mi_favicon.ico">
</head>
<body>
Hola Mundo
</body>
</html>
Refresque la página o cárguela de nuevo en el navegador. Ahora, en la pestaña verá la imagen del favicon al lado del título.
Un favicon es una imagen muy pequeña, generalmente de 16 × 16 o 32 × 32 píxeles. Puede estar almacenada en un archivo con extensión “.png”, “.gif” o, como en el ejemplo anterior, “.ico”. Si quiere utilizar alguno, puede buscar uno que encaje con sus necesidades en Internet o, aún mejor, crearlos usted mismo con un generador de favicones online. Aunque existen muchos disponibles, uno de los fáciles de usar es https://www.favicon.cc/. Fue el empleado para dibujar la inicial de mi nombre (la letra “T”). Si experimentara problemas de visualización en Chrome, acceda a esta herramienta desde otro navegador como Edge. Es muy intuitivo de manejar, por lo que empezará a crear sus propios iconos nada más abrirlo. Puede hacerlo de cero (botón “Create New Favicon”) o cargar una imagen que, con mayor o menor fortuna, la reducirá a un tamaño de 16 × 16 píxeles (botón “Import Image”). Además, en la propia pestaña de la herramienta se muestra cómo quedaría en su página web. Una vez completada la imagen, solo tiene que descargarla en su ordenador pulsando el botón “Download Favicon”.
2.4 ETIQUETAS BÁSICAS DEL CUERPO
Las etiquetas que forman parte del cuerpo de un documento HTML son las relacionadas con los elementos visibles de la página (textos, imágenes, listas, hipervínculos, etc.). Estos podrán agruparse en contenedores mediante los que sea posible aplicar un mismo estilo o situarlos de la forma deseada en una determinada zona de la pantalla.
Con el fin de describirlas de una manera ordenada, las etiquetas se estudiarán por categorías:
Texto: Hacen posible la creación de los párrafos y los encabezados con los que se estructura el contenido. [cite: 191, 192] En este grupo también se incluyen aquellas que le dan cierto formato (subrayando, poniéndolo en cursiva, etc.). Cuando el texto tiene una semántica especial como sucede, por ejemplo, con las citas literales de otras fuentes, los títulos de libros, las películas, etc., existen etiquetas específicas que permite mostrarlo de forma diferenciada.
Imágenes: Junto con el texto, componen el contenido principal de la página.
Multimedia: Incorporan archivos de audio y vídeo que complementan el contenido principal.
Hipervínculos: Si una de las principales características de la web es su carácter hipertexto, los hipervínculos son los que la hacen posible.
Listas: Imprescindibles cuando hay que organizar o clasificar información.
Contenedores: Agrupan los elementos de la página por su temática (aquello de lo que tratan) o con el fin de aplicar las mismas reglas de estilo.
Empecemos por las etiquetas que tienen que ver con el texto.
2.4.1 Texto
Aunque las páginas web actuales son cada vez más visuales y los elementos multimedia tienen un papel predominante, el texto sigue siendo, sin lugar a dudas, el protagonista. Por ese motivo, en esta sección empezará estudiando las etiquetas que permiten estructurarlo en capítulos y secciones. A continuación, se presentarán aquellas otras con las que se da formato a dicho texto, hacen posible añadir subíndices o superíndices e, incluso, realizar anotaciones al margen. En la siguiente sección conocerá un grupo de etiquetas especializado en la inserción de citas procedentes de fuentes externas o el nombre de las propias fuentes. En este grupo también se incluyen aquellas que asocian descripciones emergentes a términos que requieran una aclaración adicional, como, por ejemplo, los acrónimos. Un apartado específico dedicado a las entidades HTML le permitirá utilizar caracteres especiales que no encontrará en su teclado, con los que podrá escribir fórmulas matemáticas, añadir símbolos de uso común como los del copyright o marca registrada, etc.
Empecemos por las etiquetas más comunes: las de los encabezados y los párrafos.
2.4.1.1 Encabezados y párrafos
En esta sección se describen las etiquetas con las que se crean los párrafos que componen la información que se pretende transmitir, además de las que permiten organizarla en capítulos y apartados, tal como está acostumbrado a ver en libros y prensa. Se trata de las siguientes:
<h1> a <h6>: Representan los distintos tipos de encabezados. Estructuran el contenido en secciones a distintos niveles siguiendo el índice del documento.
<p>: Dividen el texto en párrafos.
El siguiente código de ejemplo muestra el aspecto de cada uno de estos encabezados:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>Título principal</h1>
<h2>Subtítulo</h2>
<h3>Encabezado de tercer nivel</h3>
<h4>Encabezado de cuarto nivel</h4>
<h5>Encabezado de quinto nivel</h5>
<h6>Encabezado de sexto nivel</h6>
</body>
</html>
A continuación, puede ver este documento HTML en Chrome:
Después de establecer las secciones en las que se divide el contenido de una página, estas deberán rellenarse con el texto correspondiente. La forma de hacerlo, al igual que en cualquier otro medio escrito, es mediante párrafos, fragmentos de texto con unidad temática que se separan del resto por un punto y aparte. Una vez que haya decidido qué partes de un texto conforman los párrafos, utilice la etiqueta <p> para que se vean como tales.
Con el fin de poner en práctica esta nueva etiqueta, sustituye el contenido del cuerpo del documento HTML anterior por el siguiente, en el que hay un encabezado principal y dos párrafos:
<h1>Título principal</h1>
<p>
Este es el primer párrafo del documento.
Observe que, aunque en el código HTML añado
retornos de carro, el navegador solo muestra
el del final del párrafo.
</p>
<p>
Algo que se puede comprobar al añadir este
segundo párrafo.
</p>
Ahora, Chrome mostrará el siguiente resultado:
Observe que los párrafos siempre empiezan en una línea nueva y que se incluye un margen al principio y al final para separarlo del resto de párrafos o elementos HTML de la página.
Las etiquetas anteriores ignoraron los retornos de carro añadidos al texto en el documento HTML. Aunque no es lo habitual, si quisiera que se tuvieran en cuenta, deberá emplear la etiqueta <pre>, ya que muestra en el navegador el texto tal como se ha escrito en el documento HTML.
Además de las etiquetas anteriores, merecen una mención especial estas otras dos:
<hr>: Dibuja una línea horizontal que enfatiza la separación entre textos (o cualquier otro elemento de la página).
<br>: Añade un retorno de carro.
Añada la primera etiqueta de la lista anterior entre los dos párrafos del documento HTML anterior. Al refrescar la página verá la línea de separación mencionada anteriormente.
Como indica el texto del propio párrafo, da igual el número de retornos de carro que añada al escribirlos en el documento HTML porque el navegador los ignora. Si realmente quisiera añadirlos, deberá utilizar la etiqueta <br>, que inserta un salto de línea. Así, el siguiente código de ejemplo sí mostraría correctamente las dos primeras estrofas del poema «Volverán las oscuras golondrinas», de Gustavo Adolfo Bécquer.
<p>
Volverán las oscuras golondrinas<br> en tu balcón sus nidos a colgar,<br>
y otra vez con el ala a sus cristales<br>
jugando llamarán.
</p>
<p>
Pero aquellas que el vuelo refrenaban<br> tu hermosura y mi dicha a contemplar,<br>
aquellas que aprendieron nuestros nombres...<br>
¡esas... no volverán!
</p>
Como puede comprobar, la etiqueta <br> se usa sin la de cierre. A continuación, se muestra el resultado de la ejecución de este código en Chrome:
La diferen
cia entre la etiqueta <br> y <p> es que la primera solo añade un salto de línea, mientras que la segunda agrega también un espacio de separación con el resto del texto (o cualquier otro elemento de la página).
Otra forma de escribir este poema sin usar la etiqueta <br> es haciendo que el navegador muestre el contenido del elemento tal como se escriba en el propio código HTML. Para ello, deberá utilizar la etiqueta <pre>, que sí tendría en cuenta los retornos de carro que se incluyeran. El código completo del documento HTML anterior, una vez sustituida la etiqueta <p> por <pre>, quedaría así:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<pre>Volverán las oscuras golondrinas
en tu balcón sus nidos a colgar,
y otra vez con el ala a sus cristales
jugando llamarán.
</pre>
<pre>
Pero aquellas que el vuelo refrenaban tu hermosura y mi dicha a contemplar,
aquellas que aprendieron nuestros nombres...
¡esas... no volverán!
</pre>
</body>
</html>
Podría llegar a pensar que el código anterior presenta un problema de maquetación, ya que el texto aparece desplazado a la izquierda, en vez de indentado a la derecha debajo de la etiqueta <pre> dónde está incluido. No es así, ya que, si dicho texto se hubiera desplazado a la derecha en el código, también se vería desplazado en el navegador. Recuerde que esta etiqueta muestra el texto tal como se escribe en el documento HTML (incluidos los espacios o tabuladores que añada al principio de cada línea).
Cargue de nuevo este código en Chrome o refresque la página si todavía no ha salido de ella. El resultado será el mismo del código de ejemplo anterior. En realidad, ambos textos no tienen la misma apariencia, ya que la fuente de esta etiqueta no es la misma de los párrafos sino otra de ancho fijo. En el siguiente capítulo aprenderá a utilizar las fuentes.
2.4.1.2 Formato
Cuando se incluye un encabezado o un párrafo en un documento HTML, el aspecto con el que se muestra es el establecido por defecto para cada uno de estos elementos. Si quisiera modificar el formato de dicho texto, dispone de las siguientes etiquetas:
<b> o <strong>: Muestran el texto en negrita. Aunque visualmente su resultado es el mismo, la primera solo busca llamar la atención, mientras que la segunda indica que el texto contiene información importante.
<i> o <em>: Ambas presentan el texto en cursiva, pero la segunda se reserva para términos técnicos, palabras en otro idioma, etc.
<u>: Subraya el texto.
<mark>: Resalta el texto como si se hubiera marcado con un rotulador fluorescente.
<ins>: Resalta y subraya la parte de un texto que se ha añadido al documento.
<del>: Tacha el texto.
<small>: Disminuye el tamaño del texto, algo de gran utilidad cuando se quieren hacer anotaciones como, por ejemplo, la letra pequeña de los contratos.
<sub> y <sup>: Permite trabajar con subíndices y superíndices.
El siguiente documento HTML muestra un ejemplo de uso de dichas etiquetas y el efecto que producen en el texto de una serie de párrafos:
Tal como se acaba de comentar, las entidades HTML permiten la visualización de caracteres especiales, como:
Símbolos o cualquier otro carácter que no aparece en el teclado.
Caracteres reservados del propio lenguaje HTML que el navegador podría interpretar como código, no como parte del contenido de la página.
Espacios con un tratamiento especial.
En todos estos casos, la sintaxis de una entidad HTML puede hacer referencia al nombre o el código de la entidad, según la siguiente sintaxis:
&nombre; [cite: 256, 257]
&#código;
A modo de ejemplo, la tabla mostrada a continuación incluye el nombre y el código de algunos símbolos y caracteres especiales. A diferencia de los códigos, puede que algunos nombres no estén soportados por todos los navegadores.
El siguiente párrafo contiene tres de las entidades HTML de la tabla anterior:
<p>α ≠ β</p>
Si lo incluyera en el cuerpo de una página web, obtendría una expresión matemática con la siguiente desigualdad:
Además de mostrar símbolos o caracteres especiales, las entidades se emplean para escribir caracteres del propio lenguaje HTML dentro de un texto, como, por ejemplo, ‘<’ o ‘>’. Cuando el navegador encuentra este tipo de caracteres, los interpreta como la apertura o cierre de una etiqueta (aunque forme parte del texto de un párrafo o un encabezado), lo que podría provocar errores de ejecución. Para evitarlo, en vez de dichos caracteres, deberá utilizar la entidad correspondiente. En la siguiente tabla se encuentran los caracteres reservados del lenguaje HTML vistos hasta ahora (incluye el ‘&’ o el ‘#’ utilizados para identificar una entidad):
Por ejemplo, el siguiente párrafo mostraría otra expresión matemática donde la variable ‘x’ es mayor que ‘y’.
<p>x > y</p>
Aunque en páginas sencillas el navegador muestra correctamente un texto sin necesidad de usar entidades, según vaya aumentando su complejidad se pueden llegar a provocar errores difíciles de resolver.
Por último, las entidades se emplean para dar un tratamiento especial a ciertos espacios. Un caso típico es aquel en el que se evita que el navegador parta una línea en dos en uno de dichos espacios. Por ejemplo, si se quiere evitar que la frase:
Yo suelo conducir a 40 km / h en ciudad.
Se pueda llegar a romper en alguno de estos puntos, por coincidir con el final de una línea:
Yo suelo conducir a 40 km /
/ h en ciudad.
h en ciudad
Deberá sustituir los espacios que hay antes y después de la barra (‘/’) por la entidad que representa un espacio especial (non-breaking space), cuyo nombre y código es:
[cite: 270, 271]
 
Por lo tanto, si este texto estuviera dentro de un párrafo, en vez de escribirlo así:
<p> Yo suelo conducir a 40 km / h en ciudad.</p>
Debería hacerlo de esta otra forma:
<p> Yo suelo conducir a 40 km / h en ciudad.</p>
Por otra parte, cuando un texto contenga varios espacios juntos, el navegador dejará solo uno (ignora los demás). Para evitarlo, en vez del carácter espacio use esta misma entidad. Por ejemplo, si quisiera mostrar en el navegador el texto:
Añado cinco espacios y finalizo.
No podría incluirlo en un párrafo de esta forma:
<p>Añado cinco espacios y finalizó.</p>
Ya que en el navegador aparecería lo siguiente:
Como puede observar, los cinco espacios se han convertido en uno. Para que se muestren todos, el código que tendría que escribir es:
<p>Añado cinco espacios y finalizó.</p>
Es decir, empleo un espacio y cuatro entidades non-breaking space ( ). Así, se consigue el resultado esperado, tal como se aprecia a continuación:
Las entidades descritas en esta sección son solo algunas de las muchas que se pueden utilizar en HTML. Si quiere conocerlas todas visite la página https://unicode-table.com/es/html-entities/.
2.4.1.4 Citas
El grupo de etiquetas que se va a estudiar en esta sección está formado por aquellas dedicadas a citar párrafos o textos breves de otras fuentes, indicar el nombre o el título de la obra de la que procede, dar información de contacto del autor o describir el significado de un acrónimo. Se trata de las siguientes:
<blockquote>: Contiene un párrafo tomado de otra fuente. Aparece desplazado a la derecha.
<q>: Similar al anterior, solo que, en vez de un párrafo, incluye una cita breve. Se muestra entre comillas.
<address>: Da información de contacto de una persona o entidad, ya sea una dirección de correo electrónico o postal, un teléfono, etc. Se escribe en cursiva.
<cite>: Declara el nombre de una fuente o el título de cualquier obra creativa (película, novela, etc.). También se escribe en cursiva.
<abbr>: Incluye la descripción de una abreviación o un acrónimo, que surge de forma emergente al situar el ratón encima.
Como la mejor forma de ver el efecto que producen estas etiquetas es con un ejemplo, el siguiente código utiliza algunas para citar el párrafo de un artículo publicado en una conocida revista científica:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<p>
En el artículo
<cite>
ETERNOS PARA SIEMPRE.
La vida después de la muerte
</cite> se dice lo siguiente:
<blockquote>
En definitiva, los egipcios parecen haber tratado
de ser eternos para siempre, pero en realidad,
la obsesión era poder vivir en el más allá
como en la tierra, como en su vida cotidiana.
</blockquote>
</p>
<p>
Este artículo fue tomado de la revista
<cite>
Muy Historia
</cite>
, cuya redacción se encuentra en:
<address>
C/ALCALÁ 79<br>
28009 Madrid<br>
</address>
</p>
</body>
</html>
El resultado obtenido se muestra a continuación, donde se aprecia la diferencia entre cómo se escribe un texto en HTML y cómo aparece en pantalla.
La etiqueta <abbr> tiene una naturaleza diferente a las anteriores, ya que no modifica el estilo de un texto, sino que describe el significado de un acrónimo, una abreviación o, simplemente, aporta algún tipo de información sobre una o varias palabras de una frase. Para utilizarla, solo tiene que incluirlas dentro de la etiqueta y asignar la explicación como valor del atributo title, tal como se hace en el siguiente código de ejemplo:
<h1>
Estudio del lenguaje
<abbr title="HyperText Markup Language">HTML</abbr>
</h1>
Se trata de un encabezado <h1> cuyo texto contiene la palabra “HTML”, que se ha incluido dentro de la etiqueta <abbr> con el fin de añadir su descripción en el atributo title. A continuación, se puede ver el resultado de situar el ratón sobre el acrónimo HTML:
La etiqueta <dfn> guarda cierta relación con esta última, aunque la definición del término se realiza en el propio texto (no está oculta). Únicamente muestra la palabra o expresión en cursiva para señalar que se va a definir a continuación.
2.4.2 Imágenes
Si en los orígenes de la web el texto era la única forma de transmitir información, en la actualidad las imágenes le igualan o superan en importancia. Su uso, no solo complementa la información textual, sino que también es imprescindible para atraer y hacer más agradable la experiencia de usuario. La forma de incorporar una imagen a una página web es mediante la etiqueta <img>. Se trata de una etiqueta vacía que no tiene contenido ni requiere la correspondiente de cierre. Lo que sí tiene son diversos atributos, uno de los cuales es imprescindible (src), ya que especifica la ruta de acceso o el URL a la imagen, dependiendo de si esta se encuentra en el propio servidor web o en otro diferente. En ambos casos, siempre estará almacenada en un archivo en formato JPG, GIF (permite el uso de animaciones) y PNG (pueden tener fondos transparentes). A diferencia del texto, las imágenes no forman parte de la página web, por lo que se añaden a esta en el momento de abrirse.
El siguiente documento HTML es un ejemplo de uso de esta etiqueta:
El cuerpo solo incluye la etiqueta <img> que muestra la imagen del Coliseo en el navegador. Para entender el valor de su atributo src, recuerde que en todos los ejercicios desarrollados en esta obra se utiliza la estructura de carpetas del contenido descargable, por lo que se supone que el documento HTML está ubicado en la carpeta “Capitulo2” y la imagen en la carpeta “Imágenes” (ambas al mismo nivel):
A diferencia del código de los documentos HTML, que están en carpetas con el número del capítulo correspondiente, los recursos externos se agrupan en su propia carpeta (todas debajo de “Prácticas”). Así, las hojas de estilo, las imágenes o los archivos de audio y vídeo (multimedia) se encuentran en:
/Prácticas
/CSS
/Imágenes
/Multimedia
A continuación, se muestra el resultado obtenido:
Las barras de desplazamiento horizontal y vertical delatan que solo aparece parte de la imagen. Eso es debido a que su resolución (2592 × 1944) es superior al tamaño de la ventana. Si quiere saber la resolución de una imagen en Windows, solo tiene que poner el ratón sobre el archivo que la contiene. Aparecerá una ventana emergente con el formato, la fecha de creación, la resolución (dimensiones) y el tamaño que ocupa en disco.
Para resolver este problema, la etiqueta <img> dispone de los atributos:
width: Ancho de la imagen.
height: Alto de la imagen.
La etiqueta <img> dispone de más atributos. Si tiene interés en conocerlos todos, visite la página https://developer.mozilla.org/en-US/docs/Web/HTML/Element/img.
El valor de ambas propiedades puede tomar cualquiera de las unidades de medida que estudiará en el siguiente capítulo, entre las que se encuentra el número de píxeles (px). Al fijar el ancho y el alto de una imagen, esta adquiere dichas dimensiones. Si la proporción entre ambas no coincidiera con la original, la imagen se deformaría. Para evitarlo, especifique sólo una de ellas y deje que el navegador calcule la otra. A fin de demostrarlo, sustituya la etiqueta <img> del documento anterior por esta otra:
<img src="../Imagenes/coliseo.jpg" width="200px">
A continuación, puede comprobar que la imagen se ha escalado sin deformarse hasta los 200 píxeles de ancho establecidos:
Como se ha comentado al principio de esta sección, si la imagen estuviera situada en otro servidor web, el atributo src deberá tomar como valor un URL (en vez de una ruta de acceso). En esta situación, se aconseja utilizar también el atributo alt de la etiqueta <img>, cuya función es mostrar un texto descriptivo cuando, por alguna circunstancia, esta no se pudiera llegar a obtener. Sustituya la etiqueta <img> del código anterior por esta otra:
<img src="https://www.marcombo.com/.../images/logo-marcombo.png" alt="Logo de Marcombo">
Siempre que vea puntos suspensivos en el código ("...") es que se ha omitido parte de él. En este caso, el atributo src toma la URL del logo de Marcombo, cuya dirección completa es:
Si no se pudiera acceder a dicha dirección porque la imagen hubiera cambiado de nombre, de directorio o, simplemente, no existiera, en el navegador aparecería el texto “Logo de Marcombo” asignado al atributo alt. Para comprobarlo, sustituya el nombre del archivo al que se hace referencia en el atributo src por cualquier otro y refresque la página del navegador. Ahora, el resultado sería este otro:
2.4.3 Audio y vídeo
Tal como se ha comentado en la sección anterior, en los primeros tiempos de Internet los navegadores web sólo podían mostrar texto. Afortunadamente, el aumento progresivo de la velocidad de las líneas de comunicaciones, la capacidad de procesamiento de los ordenadores y la creación de estándares, han hecho posible la incorporación de todo tipo de contenido audiovisual. Tanto es así, que incluso muchos sitios web no tendrían sentido si los navegadores no fueran capaces de reproducir audio y vídeo (YouTube es un ejemplo significativo).
Las etiquetas que permiten incorporar audio y vídeo a una página web son:
<audio>
<video>
Ambas etiquetas disponen de una serie de atributos que ofrecen cierto control sobre la reproducción del audio y del vídeo. Descubramos cuáles son y para qué sirven.
La etiqueta <audio> dispone de los siguientes atributos:
src: Es el único obligatorio, ya que contiene la ruta de acceso o el URL donde se encuentra el archivo de audio. HTML admite los formatos MP3, WAV y OGG.
controls: Muestra los controles mediante los que se puede manejar la reproducción de audio.
loop: El archivo de audio se reproduce de forma indefinida.
Además de los atributos anteriores, la etiqueta <audio> tiene otras que le pueden resultar interesantes (algunas de las cuales no funcionan en Chrome, como autoplay ). Para conocerlas todas, consulte la página https://developer.mozilla.org/es/docs/Web/HTML/Element/audio.
Aunque esta etiqueta se puede usar sin la correspondiente de cierre, se recomienda añadirla ya que, de lo contrario, no se mostraría el resto del contenido del documento HTML. Habitualmente no se incluya nada entre ambas, pero cuando se utilizan formatos que no son compatibles con todos los navegadores, se aconseja añadir un conjunto de etiquetas <source> que especifiquen distintas fuentes de audio alternativas. De esta manera, se reproduciría el primero que tuviera soportado. Cuando se emplean etiquetas <source>, la ruta o URL de acceso a los archivos de audio deberá estar en su atributo src (no en el de la etiqueta <audio>). Aunque no es imprescindible, conviene añadir también el atributo type con el tipo MIME del archivo (“audio/mp3”, “audio/wav” o “audio/ogg”, según el formato). De esta forma, el navegador dispondrá de más información a la hora de decidir cuál es el archivo que puede reproducir.
En conclusión, el código HTML de la etiqueta <audio> en el que se las fuentes de sonido se establecen mediante etiquetas <source>, quedaría así:
<audio>
<source src="ruta de acceso o URL" type="tipo MIME">
<source src="ruta de acceso o URL" type="tipo MIME">
...
</audio>
Para demostrar lo sencillo que resulta incorporar audio en una página web, el siguiente código de ejemplo reproduce un archivo musical tomado de https://www.fiftysounds.com/es/musica-libre-de-derechos/, una de las múltiples webs que permiten la descarga de música libre de derechos de autor. Su código es el siguiente:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>Siempre avanzando</h1>
<audio src="../Multimedia/Always Moving Forward.mp3" controls loop></audio>
<hr>
<cite>
Obra: Siempre Avanzando<br>
Música de https://www.fiftysounds.com/es/
</cite>
</body>
</html>
El cuerpo del documento está formado por un encabezado <h1> con el título de la obra, la etiqueta <audio> que incorpora el archivo con la música de fondo y una línea de separación <hr> con la información de reconocimiento exigida por la web de la que se ha obtenido este archivo, incluida en la etiqueta <cite>. La etiqueta <audio> tiene tres atributos: con src se especifica la ruta de acceso al archivo musical, controls muestra los controles de la reproducción y loop hace que la música suene continuamente. Una vez creada la página, cárgala en Chrome y disfrute de este fondo musical.
Si lo que se pretende es incorporar vídeo a una página, deberá utilizar la etiqueta <video>, que también dispone de una serie de atributos muy útiles. Los primeros tienen la misma función que los de audio:
src: Los formatos de vídeo soportados son MP4, WebM y OGG.
controls
loop
El resto de atributos son específicos de la etiqueta <video>:
width y height: Determinan el ancho y el alto de la imagen de vídeo.
poster: Contiene la ruta o URL de la imagen que se mostraría mientras se descarga el vídeo o antes de pulsar el botón de reproducción.
muted: Hace que el vídeo se ejecute en silencio. En cualquier momento podrá subirse el volumen con el control correspondiente.
Al igual que sucedía con la etiqueta de audio, la de vídeo también puede incluir diversas etiquetas <source> que añadan diferentes fuentes de vídeo alternativas. Así, el navegador reproduciría la primera cuyo formato tuviera soportado. En ese caso, el código HTML resultante sería:
<video>
<source src="ruta de acceso o URL" type="tipo MIME">
<source src="ruta de acceso o URL" type="tipo MIME">
...
</video>
Para demostrar lo sencillo que resulta incorporar vídeo a una página web mediante la etiqueta <video>, desarrollará una donde se pueda reproducir un vídeo casero realizado en la Plaza de España de Madrid. Su código es el siguiente:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>La Plaza de España (Madrid)</h1>
<video src="../Multimedia/Madrid.mp4" width="400px" controls>
</video>
</body>
</html>
Como puede observar, el cuerpo del documento se compone de un encabezado <h1> indicando el lugar de la grabación y la etiqueta <video> que reproduce el archivo MP4 dónde está almacenada. El valor del atributo src contiene la ruta de acceso al archivo, con width se establece el ancho del área de visualización (se deja que el alto lo calcule automáticamente el navegador) y mediante controls se muestran los controles de reproducción, tal como se aprecia en la siguiente imagen:
2.4.4 Hipervínculos
Una de las características más importantes de HTML es la de ser hipertextual. La capacidad de conectar entre sí páginas web situadas en servidores dispersos por todo el mundo puede parecer algo intrascendente, pero ha sido el detonante de la creación de una red de conocimiento, clave en la rápida expansión de Internet. Algo tan sencillo, pero, a la vez, tan potente, ha sido el medio y la causa de que actualmente todo el saber esté al alcance de unos pocos clics, lo que ha supuesto una auténtica revolución a todos los niveles.
Por lo tanto, la función principal de un hipervínculo es enlazar dos páginas web, que pueden residir en el mismo o en otro servidor web. También se emplean para acceder a secciones de una misma página en la que exista mucha información. De esa forma, en vez de tener que desplazarse por ella, se añade un índice cuyas entradas sean enlaces a los diferentes capítulos y apartados en los que se organiza el contenido. El concepto de vínculo o enlace se puede generalizar, lo que aumenta su valor al permitir el uso de servicios (como el de descarga de ficheros) o la ejecución de aplicaciones (como la de envío de correos electrónicos).
En resumen, los hipervínculos permiten acceder a:
Una página en el propio servidor web.
Una página en otro servidor web.
Una sección en la misma página web.
Hacer uso de servicios o ejecutar aplicaciones.
La etiqueta con la que se crea un hipervínculo es <a>. Dispone de diversos atributos, aunque el más importante es href, ya que apunta al recurso al que se quiere acceder (generalmente, una página web). Su valor dependerá de la naturaleza de dicho recurso, que podrá ser:
Una dirección web (URL). Muestra la página web de otro servidor.
La ruta de acceso a un archivo. Accede a un recurso dentro del propio servidor (generalmente, una página web local).
Un identificador de etiqueta. Le lleva a otra sección de la misma página.
Una dirección de correo electrónico. Arranca la aplicación de correo electrónico configurada por defecto en el dispositivo.
Un número de teléfono. Abre la aplicación del móvil que permite realizar llamadas telefónicas.
Una función JavaScript. Ejecuta código JavaScript.
Veamos con detenimiento cada uno de estos escenarios.
2.4.4.1 Enlaces a páginas de otros servidores web
Como se acaba de comentar, el uso más habitual de los hipervínculos es el acceso a otras páginas web, las cuales pueden estar ubicadas en el mismo servidor o en otro diferente. En este último caso (objeto de estudio de esta sección), el valor del atributo href de la etiqueta <a> sería su URL. Así, el siguiente documento HTML de ejemplo incluye un hipervínculo (palabra “aquí”) dentro del texto de un párrafo. Si lo pulsara, la ventana del navegador mostraría la página de búsqueda de Google:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<p>
Para realizar una búsqueda en Google,
pulse <a href="http://www.google.es">aquí</a>
</p>
</body>
</html>
A continuación, se muestra esta página en Chrome:
Si observa, el texto del enlace aparece en color azul y subrayado. Es la forma que tiene el navegador de indicar que se trata de un hipervínculo. Mientras se mantenga pulsado tomará el color rojo. A partir de ese momento adquirirá un color morado. Más adelante aprenderá a modificar el aspecto de los hipervínculos en cada uno de estos estados.
Si pulsara el enlace “aquí”, se mostraría la página del buscador Google en esa misma pestaña. Si quisiera abrirlo en otra diferente, deberá utilizar el atributo target y asignarle el valor "_blank". Para demostrarlo, sustituya el código del párrafo anterior por este otro:
<p>
Para realizar una búsqueda en Google, pulse
<a href="http://www.google.es" target="_blank">aquí</a>
</p>
Ahora, al pulsar sobre el hipervínculo se abrirá una nueva pestaña con la página de Google, tal como puede comprobar en la siguiente imagen:
Antes de terminar esta sección, debe saber que los hipervínculos no tienen por qué ser solo texto. Las imágenes también pueden realizar esta función. Para demostrarlo, sustituya el código anterior por este otro:
<p>
Pulse sobre la imagen para acceder a la página web oficial del
Coliseo.
</p>
<a href="https://www.coopculture.it/.../biglietto-colosseo-foro-palatino_24h/">
<img src="../Imagenes/coliseo.jpg" width="200px">
</a>
En esta ocasión, el hipervínculo tiene una etiqueta <img> que muestra una imagen del Coliseo con una resolución de 200 píxeles (en vez de un texto). Si pulsara sobre ella, accedería a la página oficial del Coliseo de Roma cuyo URL completa es:
Una vez modificado el documento, cargue la página en Chrome, cuyo aspecto sería el siguiente:
Pulse sobre la imagen y compruebe que aparece la página oficial del Coliseo.
2.4.4.2 Enlaces a páginas locales
Como se ha comentado al principio de esta sección, puede suceder que la página a la que se quiera llegar no esté en Internet, sino dentro del mismo sitio web. En ese caso, el valor del atributo href contendrá la ruta de acceso al archivo donde se encuentra. El siguiente ejercicio muestra la forma de acceder a una página local mediante una ruta (no un URL). Para ello, se crearán dos páginas. La primera representa la página raíz ( home ) de un sitio web y su código estará almacenado en el archivo “index.html” ubicado en la carpeta “Capitulo2”. El código de la segunda página (archivo “pagina-local.html”) estará localizado en la subcarpeta “CarpetaLocal”, creada previamente dentro de “Capitulo2”. Por lo tanto, la estructura de directorios utilizada es:
El código HTML de la página raíz (archivo “index.html”) es el siguiente:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Página home</title>
</head>
<body>
<p>
Si quiere acceder a la otra página del servidor pulse
<a href="./CarpetaLocal/pagina-local.html">aquí</a>
</p>
</body>
</html>
En la cabecera se utiliza la etiqueta <title> para asignar el título “Página home” a la pestaña del navegador en la que se muestre (además de establecer que el juego de caracteres sea UTF-8). El cuerpo se compone únicamente de un párrafo, dentro del que hay un hipervínculo cuyo atributo href contiene la ruta relativa del archivo donde se almacena la página local:
"./CarpetaLocal/pagina-local.html"
El aspecto de esta página es el mostrado a continuación.
Todavía no pulse sobre la palabra “aquí”, ya que antes tendrá que crear la página a la que se accede desde el hipervínculo que tiene asociado. Su código es el siguiente:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Página local</title>
</head>
<body>
<p>
Si quiere volver a la página <i>home</i>
pulse <a href="../index.html">aquí</a>
</p>
</body>
</html>
La etiqueta <title> de la cabecera establece que el título de esta nueva página sea “Página local”. De nuevo, en el cuerpo solo hay un párrafo con un vínculo que, en este caso, permite acceder al archivo “index.html” ubicado en el directorio padre (el anterior en la estructura de directorios):
"../index.html"
Una vez guardado este segundo archivo con el nombre “pagina-local.html” en la carpeta “CarpetaLocal”, cárguela en Chrome.
Ahora, al pulsar sobre el enlace “aquí” de esta nueva página volvería de nuevo a la página home.
Si los archivos de la página anterior residieran en un servidor web en vez de en su propio ordenador, también sería posible acceder a ellos a través de su URL, en concreto:
http://nombre de dominio/index.html
http://nombre de dominio/CarpetaLocal/pagina-local.html
En el primer URL se podría obviar el nombre de la página home (“index.html”) ya que por defecto sería la que se cargaría. Cuando aprenda a utilizar un servicio de hosting web en un capítulo posterior, realizará un ejercicio que lo demuestra.
2.4.4.3 Enlaces a secciones de una misma página
Además de poder acceder a otras páginas web, los hipervínculos también permiten mostrar secciones pertenecientes a la misma página. Son útiles cuando esta tiene mucho contenido y requieren desplazarse continuamente por ella para encontrar el que se busca. Para evitarlo, se suele crear un índice cuyas entradas son enlaces que llevan a los diferentes capítulos o apartados de la página.
Para que un hipervínculo le dirija a la sección de una misma página (en vez de a otra diferente), el valor del atributo href deberá ser el identificador asignado a la sección correspondiente, precedido del carácter almohadilla (“#”). Su sintaxis es:
#identificador
Pero ¿cómo se asocia un identificador a la sección de una página? Mediante el atributo id en la etiqueta de inicio, tal como puede ver a continuación:
<etiqueta id="identificador">
Para comprobarlo, imagine que tiene una página formada por tres capítulos de cierto tamaño, al principio de la cual hay un índice desde el que se puede acceder directamente a cualquiera de ellos. Asimismo, al final de cada capítulo hay un enlace que le lleva de regreso al índice (el inicio de la página). El código de dicho documento HTML podría ser algo así:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<h1 id="índice">Índice</h1>
<a href="#capítulo 1">Capítulo 1</a><br>
<a href="#capítulo 2">Capítulo 2</a><br>
<a href="#capítulo 3">Capítulo 3</a><br>
<h1 id="capítulo 1">Capítulo 1</h1>
<p>Este es el texto del capítulo 1</p>
...
<p>Este es el texto del capítulo 1</p>
<a href="#índice">Volver al índice</a>
<h1 id="capítulo 2">Capítulo 2</h1>
<p>Este es el texto del capítulo 2</p>
...
<p>Este es el texto del capítulo 2</p>
<a href="#índice">Volver al índice</a>
<h1 id="capítulo 3">Capítulo 3</h1>
<p>Este es el texto del capítulo 3</p>
<p>Este es el texto del capítulo 3</p>
...
<a href="#índice">Volver al índice</a>
</body>
</html>
Los puntos suspensivos no forman parte del código HTML. Indican que el resto de líneas son iguales a la de arriba.
En dicho código aparecen cuatro etiquetas <h1> que establecen las secciones en las que se va a dividir el documento: “Índice”, “Capítulo 1”, “Capítulo 2” y “Capítulo 3”:
Todos los capítulos tienen un identificador, que será utilizado en el correspondiente hipervínculo del índice. Este último también tiene un identificador (el valor de su atributo id es “índice”), ya que todos los capítulos tienen un enlace al final desde el que se podrá volver al índice.
Los hipervínculos, a diferencia de los párrafos, se muestran uno al lado del otro. Para que aparezcan debajo, se ha añadido la etiqueta <br> después de cada uno:
Cada capítulo está formado por un número indefinido de párrafos con el contenido de la sección (etiquetas <p>) y un hipervínculo que permite acceder al índice (la misma etiqueta <a> en todos los capítulos):
<a href="#índice">Volver al índice</a>
En la parte superior izquierda de la siguiente imagen aparece la página que se acaba de desarrollar en el momento de abrirla en su navegador (o después de pulsar sobre el enlace “Volver al índice” situado al final de cualquiera de los capítulos). En la parte inferior derecha se muestra lo que vería al pulsar sobre el enlace “Capítulo 2” del índice.
Observe que en la pestaña donde se muestra la página, además del nombre del archivo HTML (o título, si se hubiera indicado en la cabecera) aparece el identificador de la sección a la que se ha accedido, precedido del carácter almohadilla (“#”).
2.4.4.4 Enlaces a servicios y aplicaciones
Muchas de las páginas que ofrecen productos o servicios tienen algún tipo de mecanismo de comunicación que nos permite ponernos en contacto con ellos para solicitar información, resolver dudas, etc.
Unas ocasiones se emplean formularios con una serie de campos que hay que rellenar, pero en otras se da la posibilidad de enviar un correo electrónico o realizar una llamada telefónica (si el acceso se realiza desde un móvil) con solo pulsar un enlace. En estos dos últimos casos, el atributo href deberá tomar uno de estos valores:
mailto:dirección de correo electrónico
tel:número de teléfono
A continuación, se muestra un código de ejemplo del primer tipo:
<p>
Para enviar un correo a Tomás,
pulse <a href="mailto:mi.correo@gmail.com">aquí</a>
</p>
En la siguiente imagen puede ver la página HTML y la aplicación de correo Outlook (es la que tengo configurada por defecto en mi ordenador) que se ha abierto tras pulsar sobre el enlace “aquí”. Como puede apreciar, el campo “Para…” aparece rellenado con mi dirección de correo electrónico.
Si está interesado en saber cómo rellenar automáticamente el resto de campos de un correo electrónico, como el del asunto, con copia a, con copia oculta o, incluso, el propio cuerpo del mensaje, consulte la página https://developer.mozilla.org/es/docs/Learn/HTML/Introduction_to_HTML/Creating_hyperlinks.
La siguiente facilidad que proporcionan los hipervínculos tiene que ver con la descarga de cualquier tipo de archivos a su ordenador personal, algo que seguro que realiza con cierta frecuencia para bajarse imágenes, música, programas, formularios, etc. En este caso, además de asignar al atributo href la ruta del archivo que se pretende descargar, deberá añadir el atributo download a la etiqueta <a>. Así, el siguiente código de ejemplo permitiría la descarga de una imagen almacenada en el archivo “imagen-descargable.jpg”, situado en la misma carpeta que la página HTML:
<p>
Para descargar la imagen
pulse <a href="./imagen-descargable.jpg" download>aquí</a>
</p>
Si quiere conocer todos los atributos de la etiqueta <a>, consulte la página: https://developer.mozilla.org/es/docs/Web/HTML/Element/a.
2.4.5 Listas
Desde un punto de vista conceptual, las listas sirven para crear enumeraciones con un cierto propósito. Se utilizan con frecuencia, ya que son un método eficaz de clasificación. También se emplean para crear índices cuyas entradas sean los hipervínculos que lleven al capítulo o sección correspondiente dentro de la misma página. Incluso, sus elementos pueden constituir la barra de navegación de la página o el sitio web, ya que, como aprenderá en un capítulo posterior, son totalmente configurables.
Hay dos tipos de listas, aquellas que no tienen un orden específico y las que cada elemento viene precedido por un número que determina su posición. En el primer caso se utiliza la etiqueta <ul> y en el segundo <ol>. En realidad, estas etiquetas representan un contenedor dentro del que se incluyen sus elementos mediante la etiqueta <li>. El nombre de la etiqueta “ul” es el acrónimo de unordered list (lista sin orden o desordenada), el de “ol” es ordered list (lista ordenada) y el de “li” list item (elemento de la lista).
El siguiente código de ejemplo muestra cómo se utilizan estas etiquetas:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<ul>
<li>Primer elemento de la lista</li>
<li>Segundo elemento de la lista</li>
<li>Tercer elemento de la lista</li>
</ul>
</body>
</html>
A continuación se muestra el aspecto de la lista una vez cargado en Chrome.
Ahora, cambie la etiqueta <ul> por <ol>. El resultado será este otro:
El uso de uno u otro tipo de lista dependerá de sus necesidades concretas. Más adelante, cuando aprenda a crear sus propios estilos, conocerá las propiedades que permiten modificar tanto el aspecto de la lista como el de cada uno de sus elementos.
Además de las listas anteriores, HTML proporciona las listas de descripciones, cuyos elementos deben ser específicamente términos y sus descripciones. Así, con la etiqueta <dl> crearía la lista, con <dt> se identificaría el término y con <dd> se añadiría su descripción. Para más información, visite la página https://developer.mozilla.org/en-US/docs/Web/HTML/Element/dl.
2.4.6 Contenedores
El código HTML no es un código plano en el que se van añadiendo elementos secuencialmente, sino que se organiza de forma jerárquica. El nivel superior de esta jerarquía se establece con la etiqueta <html>, dentro de la que los elementos que aportan la metainformación se agrupan en la etiqueta <head> y los visibles en la etiqueta <body>. Por lo tanto, <html> es un contenedor que agrupa el contenido de la página web en otros dos contenedores: <head> y <body>.
En informática, una estructura jerárquica se representa en forma de árbol, donde los elementos que están en la parte superior contienen los que hay por debajo. A los primeros se les conoce como nodos padre y a los segundos nodos hijo. En consecuencia, cualquier página web tendrá la siguiente estructura jerárquica:
<html>
/ \
<head> <body>
Cuando se realiza el diseño gráfico de una página, lo que se hace es añadir elementos HTML debajo de las ramas <head> y <body>, creando nuevos niveles en la jerarquía donde, además de relaciones de pertenencia padre-hijo, existen otras de herencia que tendrá que conocer para obtener el resultado deseado. En las siguientes secciones estudiará los contenedores semánticos que proporciona HTML para organizar la información de una página web de forma estándar, así como otros de carácter general que le permitirán hacerlo de acuerdo a sus propios criterios.
2.4.6.1 Contenedores semánticos
Cuando se diseña una página web, los elementos visibles se agrupan de acuerdo a la temática de su contenido (aquello de lo que tratan) y luego se les da forma con reglas de estilo. Aunque hay tantos diseños como se pueda llegar a imaginar, la siguiente imagen muestra uno de carácter general comúnmente aceptado, motivo por el que HTML ofrece etiquetas para cada una de las áreas que lo componen:
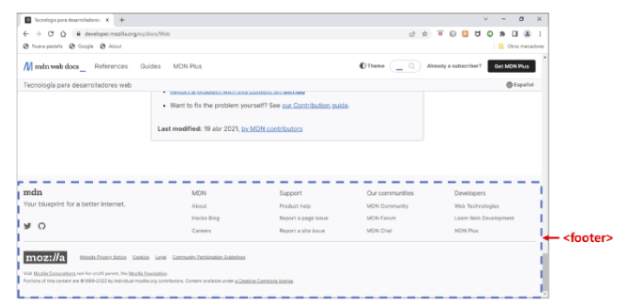
La cabecera se representa con la etiqueta <header> (no la confunda con <head>), la barra de navegación con <nav>, el contenido principal con <main>, el contenido relacionado con <aside> y el pie con <footer>. Todas estas etiquetas son contenedores semánticos porque solo incluyen información de un tipo específico. Aunque se usan fundamentalmente para el diseño de la página, al delatar la naturaleza de su contenido son empleadas por los buscadores para indexarla de forma adecuada. En cualquier caso, ninguna de ellas determina el aspecto con el que se muestra en pantalla. Por ese motivo, aunque en la imagen anterior el área del contenido principal sea más grande que el resto o la del contenido relacionado esté a la derecha del anterior, solo es una forma de representarlo, ya que eso será algo que tendrá que establecer mediante las adecuadas reglas de estilo.
Veamos en detalle el tipo de información que abarca cada una de estas etiquetas.
En la parte superior de la página se sitúa la cabecera, en la que habitualmente se ofrecen datos básicos de la empresa, la marca o el propio sitio web, por lo que suele estar formada por un logo y su nombre. Esta información se incluye en la etiqueta <header>, que, por su naturaleza, suele ser la misma en todas las páginas del sitio.
En la etiqueta <nav> se encuentra la barra de navegación desde la que se accede a las principales partes del sitio web. Está formada por una serie de enlaces o menús donde no suele faltar una opción que lleve a una página en la que se ofrezca una breve descripción de la empresa, la marca o el sitio, un catálogo de productos o servicios y los datos de contacto. Aunque en la imagen anterior se sitúe debajo de la cabecera, cada vez con más frecuencia forma parte de esta.
El contenido principal debe ir dentro de la etiqueta <main> y constituye la información por la que el usuario accede a la página. Se suele organizar por secciones o artículos que tratan de temas específicos e independientes de los demás. Para crear una sección se utiliza la etiqueta <section>, mientras que los artículos se construyen con <article>.
El contenido de la etiqueta <aside> abarca todo lo que está relacionado con el principal, por lo que varía mucho en función de la naturaleza de la página. Se trata de información secundaria que suele estar compuesta de enlaces a artículos relacionados, a otros sitios web, los últimos post publicados (agrupados por categorías o etiquetas), anuncios, etc.
Por último, la etiqueta <footer> suele incluir de nuevo el logo de la empresa (igual que en la cabecera), así como los datos de contacto y los enlaces a la política de privacidad o legal, a los términos de uso del producto o servicio ofrecido, a las redes sociales, etc.
En resumen, la estructura jerárquica de una página web que sigue este diseño es la siguiente:
La jerarquía sólo muestra la relación de pertenencia entre elementos, no la posición que ocupan en pantalla ni entre ellos. Debajo de cada etiqueta irían los elementos HTML que contienen, que pueden ser elementos primitivos u otros contenedores. En este último caso, la jerarquía iría creciendo hacia abajo. Por ejemplo, en la cabecera es habitual que haya una imagen o un logo al lado del texto que identifique el sitio web, en la barra de navegación una lista de enlaces que permite navegar por las principales páginas de dicho sitio, etc. En la jerarquía anterior (estructura en árbol), esto se traduce en ramificaciones hacia abajo, como la presentada en esta otra imagen, donde se ha desarrollado la parte correspondiente a la cabecera:
Ahora la jerarquía consta de tres niveles: el de la página HTML, el del contenido visible y el de la cabecera. Con el resto de secciones se haría lo mismo y, seguramente, eso traería consigo nuevos niveles. Es importante conocer la posición de cada elemento en la jerarquía, ya que estos heredarán muchas de las características visuales de sus ancestros, las cuales pasarán, a su vez, a la descendencia. En los ejercicios que haga en la siguiente sección practicará este mecanismo de herencia.
A modo de ejemplo, se muestra una de las páginas del sitio web de Mozilla (utilizado como referencia en este libro) que sigue el diseño descrito.
Observe como se funde la barra de navegación y la cabecera en la parte superior. Haciendo scroll hacia abajo, verá la información del pie de página.
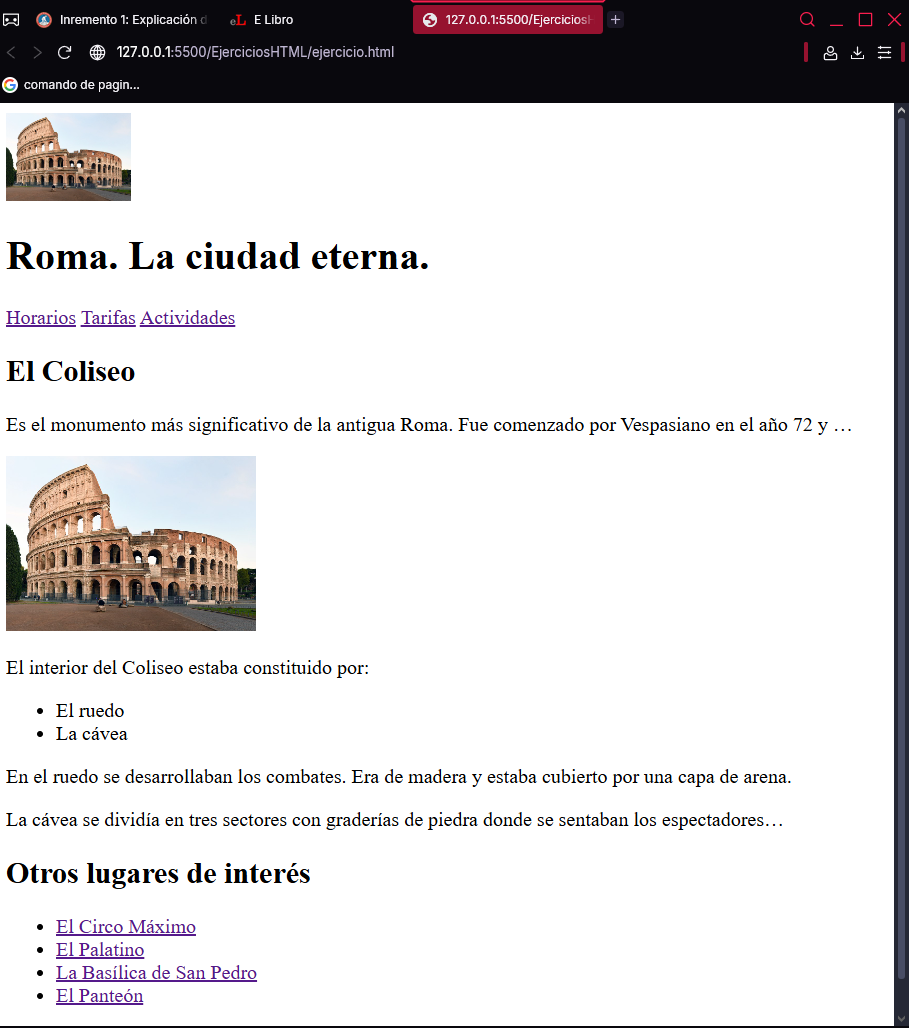
Para finalizar esta sección, desarrollará un documento HTML que sigue el diseño estándar. Se trata de una página cuyo objetivo es dar a conocer los principales lugares de interés de Roma. El código HTML de dicha página es el siguiente:
El cuerpo del documento HTML está formado por las etiquetas semánticas descritas en esta sección: <header>, <nav>, <section>, <aside> y <footer>. Analicemos por separado el código de cada una de ellas. Como el contenido principal de la página sólo se compone de una sección, por simplicidad se ha omitido la etiqueta <main>.
La cabecera del documento está formada por una imagen cuyo ancho se ha limitado a 100 píxeles y un encabezado <h1>:
<header>
<img src="../Imagenes/templo-saturno2.JPG" width="100px">
<h1>Roma. La ciudad eterna.</h1>
</header>
La barra de navegación está formada por tres hipervínculos que informarían de los horarios, tarifas y actividades de cada lugar de interés:
El contenido principal se compone de un encabezado <h1>, una serie de párrafos que describen el Coliseo, una lista con sus partes estructurales y una imagen representativa de 200 píxeles de ancho:
<section>
<h1>El Coliseo</h1>
<p>
Es el monumento más significativo de la antigua Roma. Fue
comenzado por Vespasiano en el año 72 y ...
</p>
<img src="../Imagenes/coliseo.jpg" width="200px">
<p>
El interior del Coliseo estaba constituido por:
</p>
<ul>
<li>El ruedo</li>
<li>La cávea</li>
</ul>
<p>
En el ruedo se desarrollaban los combates. Era de madera y estaba cubierto por una capa de arena.
</p>
<p>
La cávea se dividía en tres sectores con graderías de piedra
donde se sentaban los espectadores...
</p>
</section>
Los puntos suspensivos representan el texto que se ha omitido para no hacer innecesariamente largo el código.
El contenido relacionado vuelve a tener un encabezado <h1> y una lista de hipervínculos a otros lugares de interés:
<aside>
<h1>Otros lugares de interés</h1>
<ul>
<li><a href="#">El Circo Máximo</a></li>
<li><a href="#">El Palatino</a></li>
<li><a href="#">La Basílica de San Pedro</a></li>
<li><a href="#">El Panteón</a></li>
</ul>
</aside>
Por último, el pie de página solo muestra el nombre del autor:
Aunque el código HTML esté completo y se hayan usado las etiquetas semánticas adecuadas, la página no tendrá el mismo aspecto que la imagen anterior, sino la siguiente:
Salta a la vista que el contenido de cada etiqueta se sitúa debajo de la anterior (excepto los hipervínculos, que se muestran en línea). El motivo es porque las etiquetas semánticas solo se encargan de agrupar por secciones según su temática, pero no intervienen en la forma de mostrarlo, responsabilidad de las hojas de estilo. En un capítulo posterior, una vez adquiridos los conocimientos necesarios, desarrollará la que permita darle la apariencia deseada.
2.4.6.2 Contenedores genéricos
Las etiquetas estudiadas anteriormente eran contenedores semánticos porque su información sólo podía ser de un tipo específico. Sin embargo, hay otros motivos para agrupar un conjunto de elementos HTML:
Organizarlos físicamente en la pantalla, asignándoles un determinado espacio y posición.
Crear un estilo visual homogéneo mediante una paleta de colores, una familia de fuentes, etc.
La temática de su contenido no se ajusta a ninguno de los contenedores semánticos estudiados anteriormente.
La etiqueta que permite utilizar este tipo de contenedor genérico es <div>. Aunque sus usos son muy variados, se empleará generalmente para aglutinar aquellos elementos que compartan las reglas de estilo que establezcan su apariencia o posición en la página según un determinado diseño gráfico.
Con el fin de entender la función de este tipo de contenedores, va a realizar una serie de ejercicios en los que se recurre a ellos para cambiar de forma conjunta el aspecto de un grupo de párrafos. Aunque sea objeto de estudio del siguiente capítulo, para entender estos ejercicios debe saber que una de las formas de cambiar la apariencia de cualquier elemento HTML es asignar ciertos valores a una serie de características visuales (propiedades) mediante el atributo style de la siguiente forma:
style="propiedad: valor; propiedad: valor; ..."
Así, por ejemplo, las propiedades que se van a manejar en los ejemplos de esta sección son:
font-family: Establece el tipo de fuente del texto. En los códigos de ejemplo se utilizará cursive (no la confunda con el estilo de letra cursiva o itálica estudiada en una sección anterior, cuyo nombre procede de esta fuente), arial y fantasy.
color y background-color: Determina el color de tinta y el de fondo.
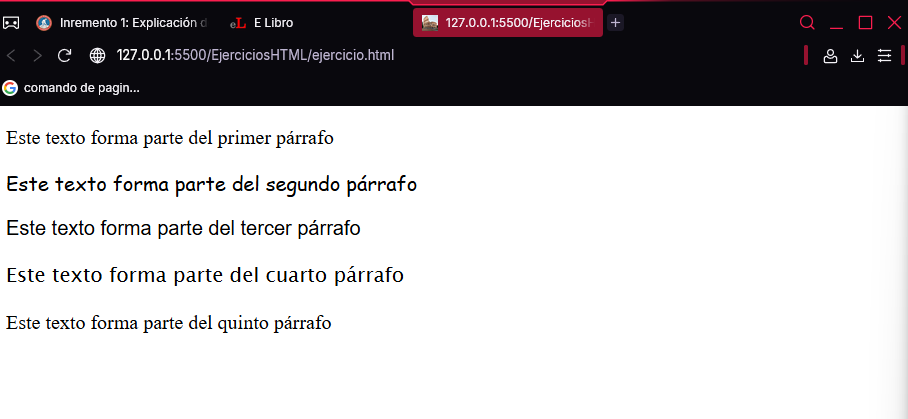
Ahora, escriba el siguiente código en el que no hay ningún contenedor:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<p>Este texto forma parte del primer párrafo</p>
<p style="font-family: cursive;">
Este texto forma parte del segundo párrafo
</p>
<p style="font-family: cursive;">
Este texto forma parte del tercer párrafo
</p>
<p style="font-family: cursive;">
Este texto forma parte del cuarto párrafo
</p>
<p>Este texto forma parte del quinto párrafo</p>
</body>
</html>
Dicho código muestra el texto del primer y último párrafo con la fuente por defecto (no se ha especificado ningún estilo), mientras los tres centrales aparecen en cursive, tal como puede ver a continuación:
Este ejemplo es muy sencillo y está formado solo por cinco párrafos, pero una página web real puede tener muchos. Imagine que quiere que todo el texto se muestre en cursiva. Tendría que repetir dicho estilo en todos y cada uno de los párrafos. La labor se complica aún más si el estilo está compuesto de múltiples propiedades (por ejemplo, además de la fuente, el color y el tamaño de los caracteres, etc.) o si dichos párrafos se reparten en secciones con sus propios estilos. A todo esto, hay que sumar el hecho de que, si en un futuro quisiera cambiar el aspecto de la página, tendría que rehacer el estilo en todas las etiquetas. Eso supondría un enorme trabajo que dificultaría el mantenimiento del sitio web.
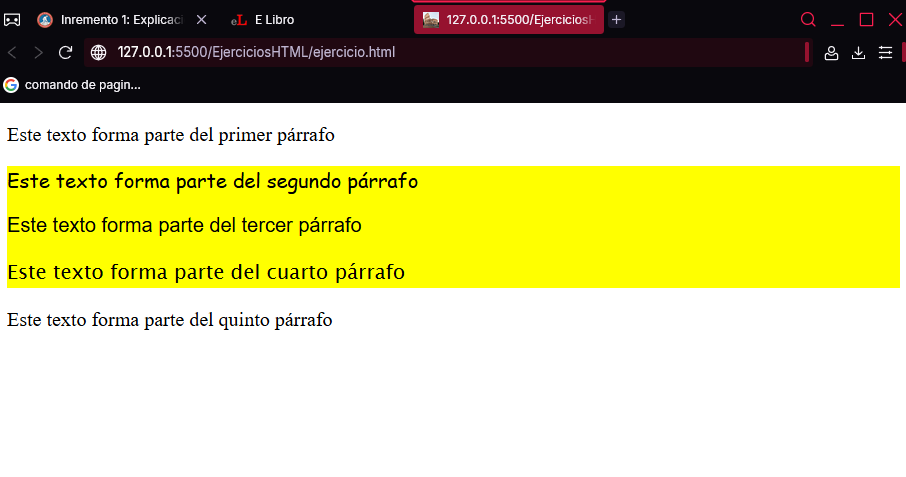
Para simplificar esta tarea, lo que se hace es agrupar los elementos en contenedores. De esa forma, solo sería necesario definir el estilo una sola vez en el contenedor <div>, ya que los elementos contenidos lo heredarían. El siguiente código agrupa los dos párrafos centrales del ejercicio anterior en un contenedor donde se define su estilo (en vez de en los propios párrafos):
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<p>Este texto forma parte del primer párrafo</p>
<div style="font-family: cursive; background-color: yellow;">
<p>Este texto forma parte del segundo párrafo</p>
<p>Este texto forma parte del tercer párrafo</p>
<p>Este texto forma parte del cuarto párrafo</p>
</div>
<p>Este texto forma parte del quinto párrafo</p>
</body>
</html>
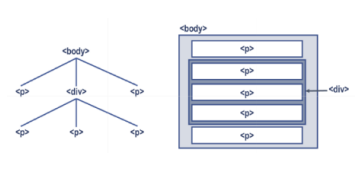
Aparte del tipo de fuente (propiedad font-family), al contenedor <div> se le ha añadido la propiedad background-color para delimitar el espacio que ocupa. Así, se puede identificar claramente los párrafos que incluye.
A la derecha se muestran los cinco párrafos tal como aparecen en la pantalla del navegador (simbolizada por la etiqueta <body>), donde se aprecia que los tres párrafos centrales están dentro de un contenedor <div>. A la izquierda, estos mismos elementos se representan de forma jerárquica. En la parte superior se encuentra el cuerpo del documento, debajo del que están los dos párrafos y el contenedor. A su vez, este último está formado por otros tres párrafos situados en un segundo nivel de la jerarquía.
Según dicha jerarquía, si en la etiqueta <body> se hubiera especificado un estilo, este sería heredado por los elementos hijos, es decir, los situados en el nivel inferior (en ese caso, los dos párrafos y el contenedor). Asimismo, los dos párrafos del contenedor <div> (situados en un segundo nivel) heredarían el estilo de dicho contenedor, que podría ser el heredado de la etiqueta <body> o el establecido en la propia etiqueta <div>. Puesto que todos los elementos HTML pueden fijar su propio estilo y heredar el de los ancestros, ¿qué sucedería si estos entraran en contradicción? Por ejemplo, si en el cuerpo del documento se indicara que la fuente debe ser cursive, y en el contenedor o en el párrafo fuera arial. En ese caso, la regla es que siempre prevalece el estilo definido en el elemento más específico, es decir, el que está situado más abajo en la jerarquía.
El siguiente código de ejemplo muestra cómo se aplica un estilo a un conjunto de párrafos cuando este se establece en el cuerpo del documento, en un contenedor o en la propia etiqueta del párrafo:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<body style="font-family: cursive;">
<p>Este texto forma parte del primer párrafo</p>
<div style="font-family: arial; background-color: yellow;">
<p>Este texto forma parte del segundo párrafo</p>
<p style="font-family: fantasy;">Este texto forma parte del tercer párrafo</p>
<p>Este texto forma parte del segundo párrafo</p>
</div>
<p>Este texto forma parte del cuarto párrafo</p>
</body>
Al haber establecido un estilo de fuente cursive en el cuerpo del documento (etiqueta <body>), por defecto todos los párrafos de la página se escribirían con dicha fuente. Sin embargo, eso solo sucede con el primero y el último, ya que los tres intermedios están dentro de un contenedor <div> en el que se ha especificado su propia fuente (arial). No obstante, solo se escriben con esta el primer y el tercer párrafo, ya que en la etiqueta del segundo se fija una tercera fuente (fantasy).
La siguiente imagen muestra el resultado obtenido:
El mecanismo de herencia es aplicable a cualquier tipo de contenedor (incluso los semánticos). En cualquier caso, debe saber que no todas las propiedades se heredan.
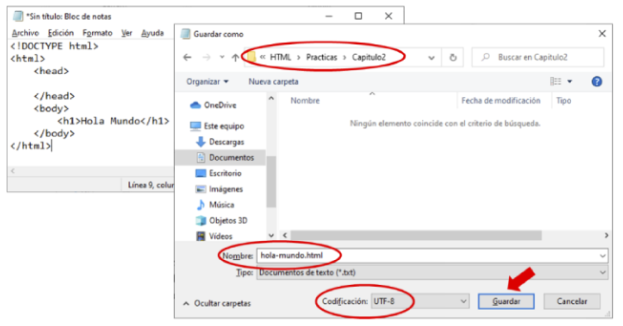

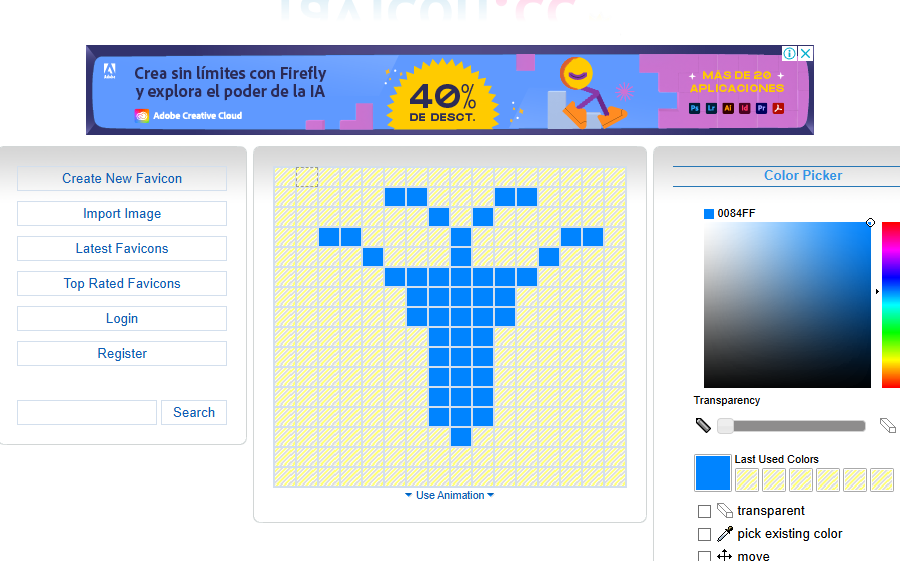

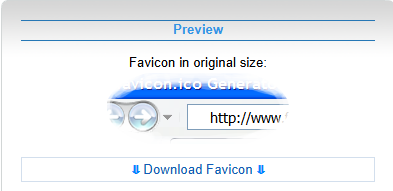
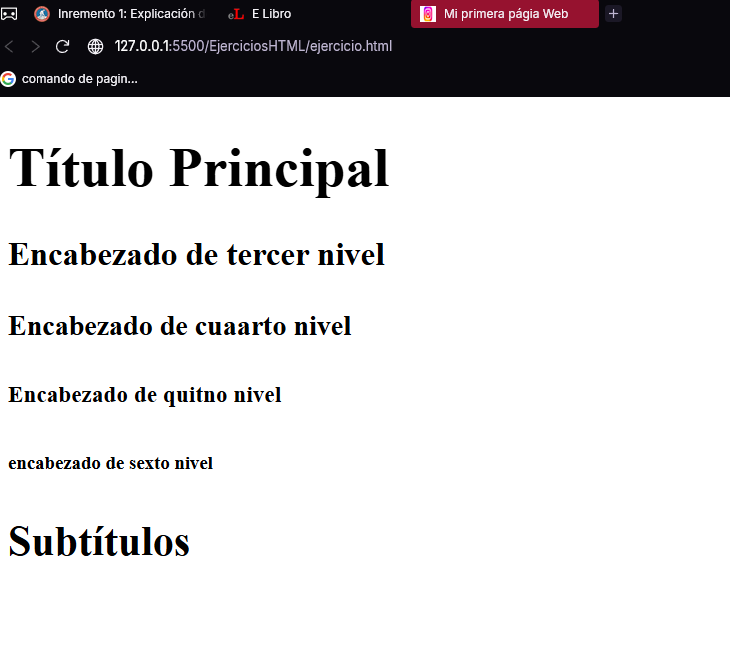
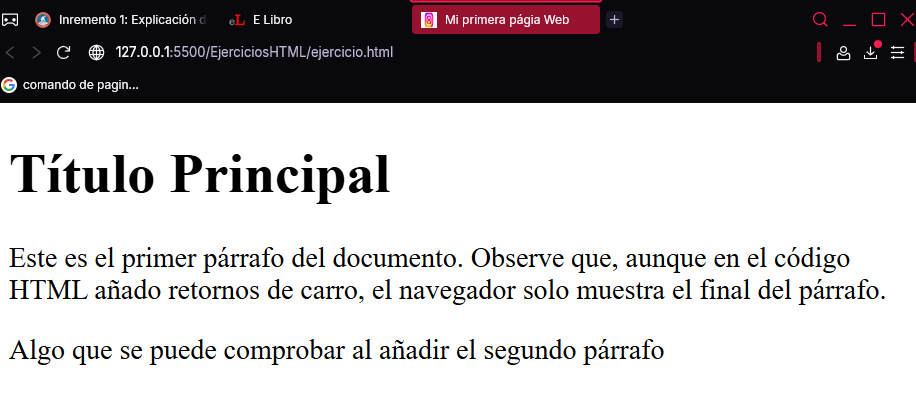
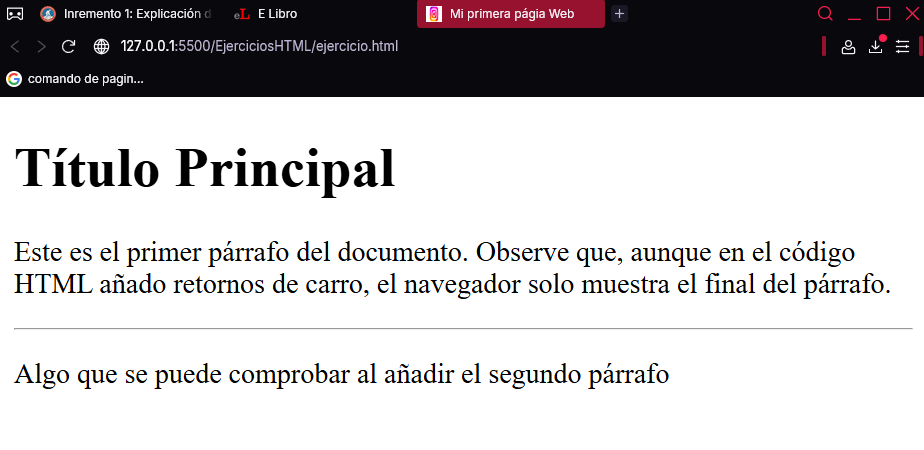
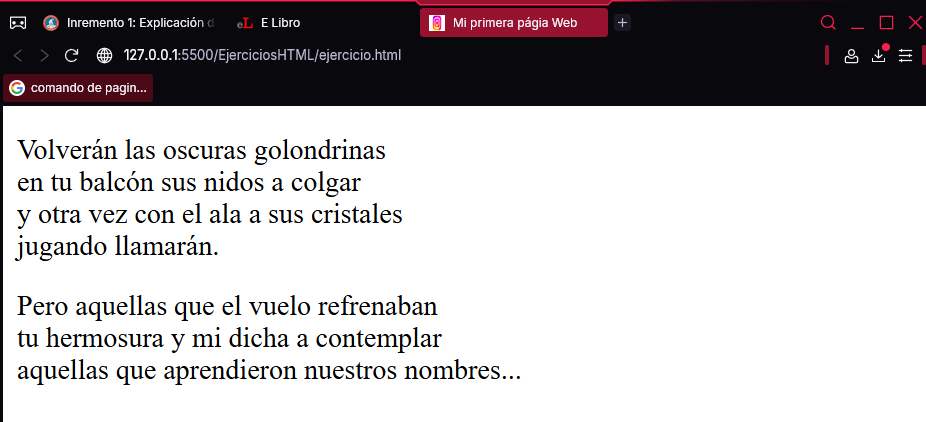
 Habrá observado que el texto del último párrafo no coincide con lo que muestra el navegador, ya que “©” se ha convertido en el símbolo copyrigth (©). En realidad, se trata de un carácter especial del que no dispone su teclado. Al igual que este, hay otros muchos símbolos de tipo técnico, matemático, letras griegas, monedas, etc., que seguramente necesite utilizar en sus propias páginas web. Para incorporarlos, deberá hacerlo como entidades HTML, objeto de estudio de la siguiente sección.
Habrá observado que el texto del último párrafo no coincide con lo que muestra el navegador, ya que “©” se ha convertido en el símbolo copyrigth (©). En realidad, se trata de un carácter especial del que no dispone su teclado. Al igual que este, hay otros muchos símbolos de tipo técnico, matemático, letras griegas, monedas, etc., que seguramente necesite utilizar en sus propias páginas web. Para incorporarlos, deberá hacerlo como entidades HTML, objeto de estudio de la siguiente sección. 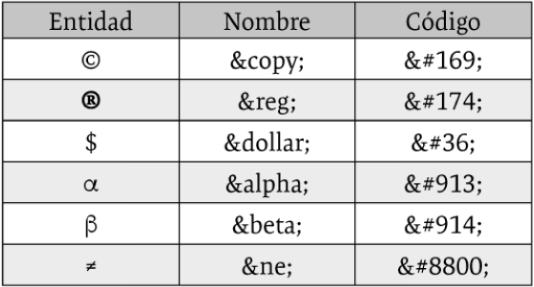
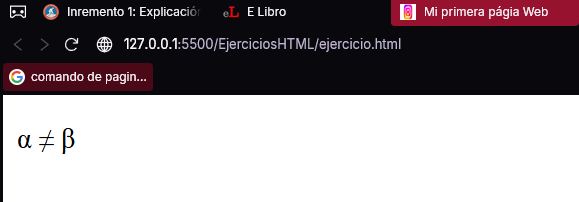
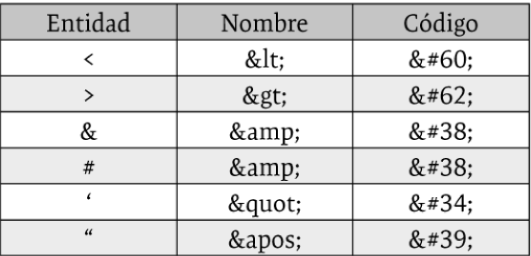
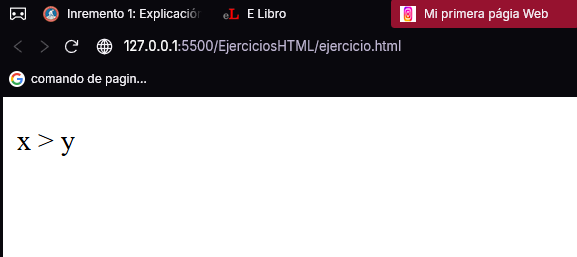
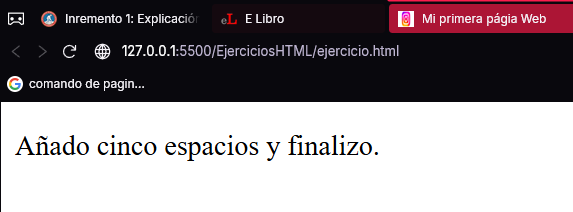
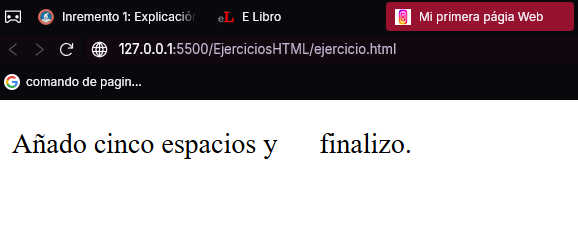
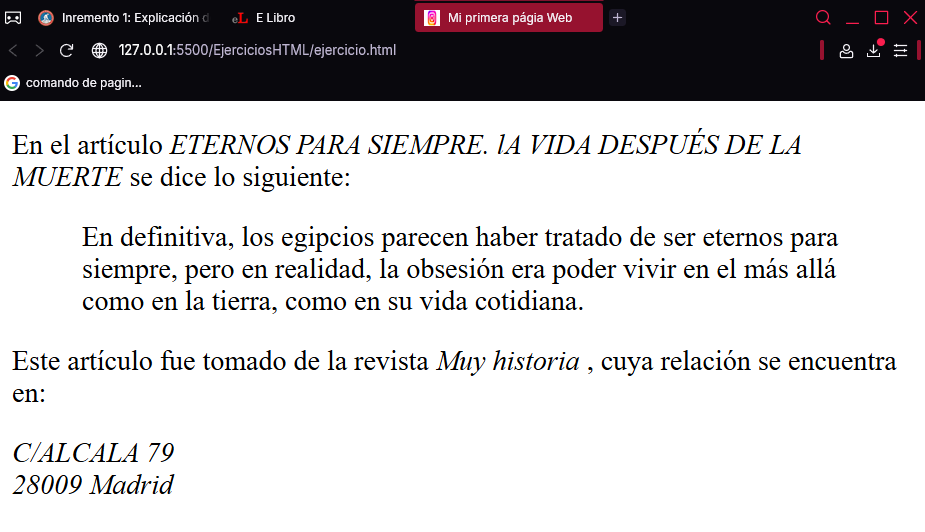
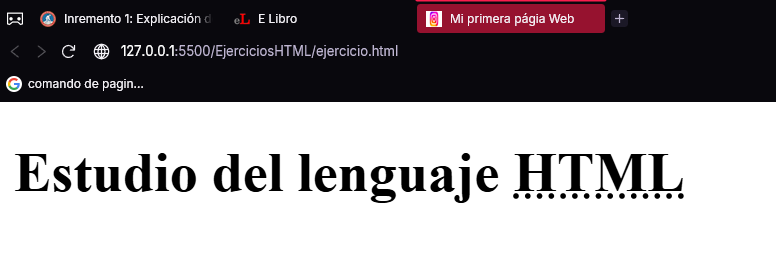
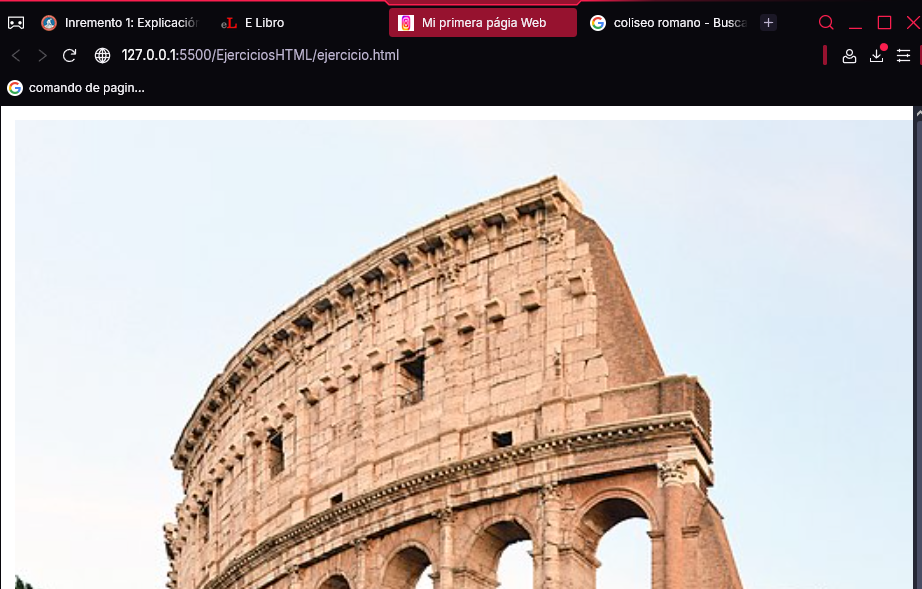
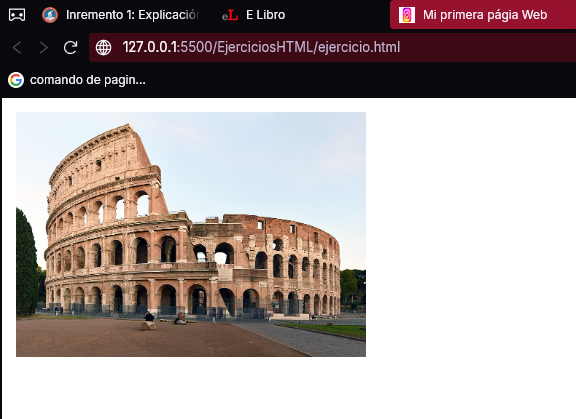

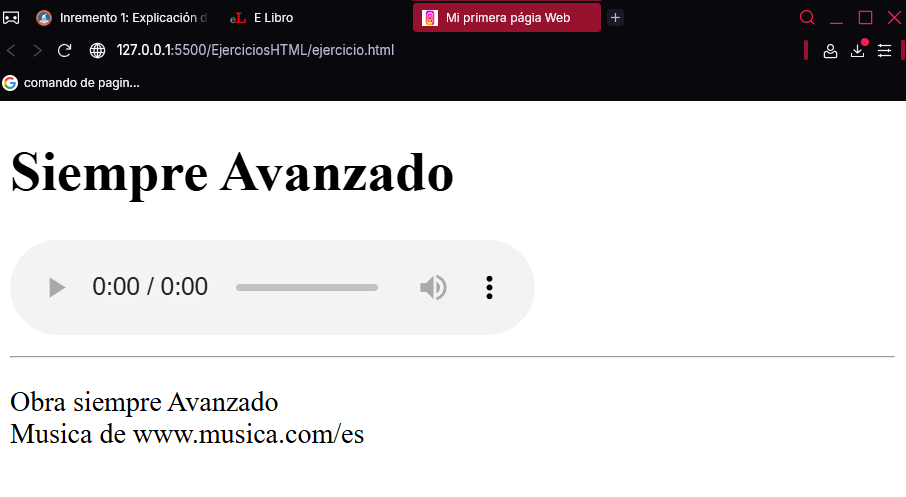

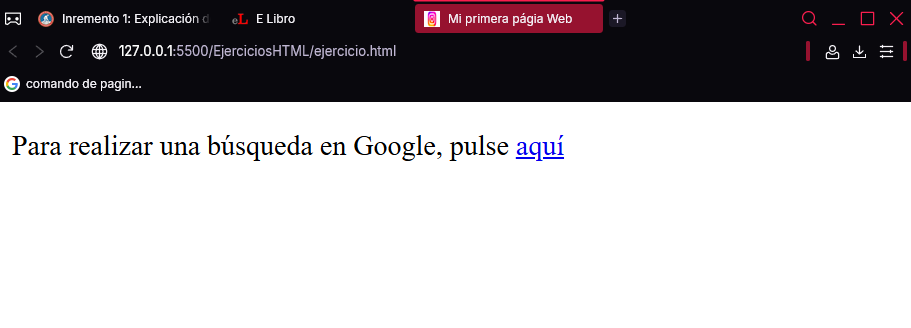
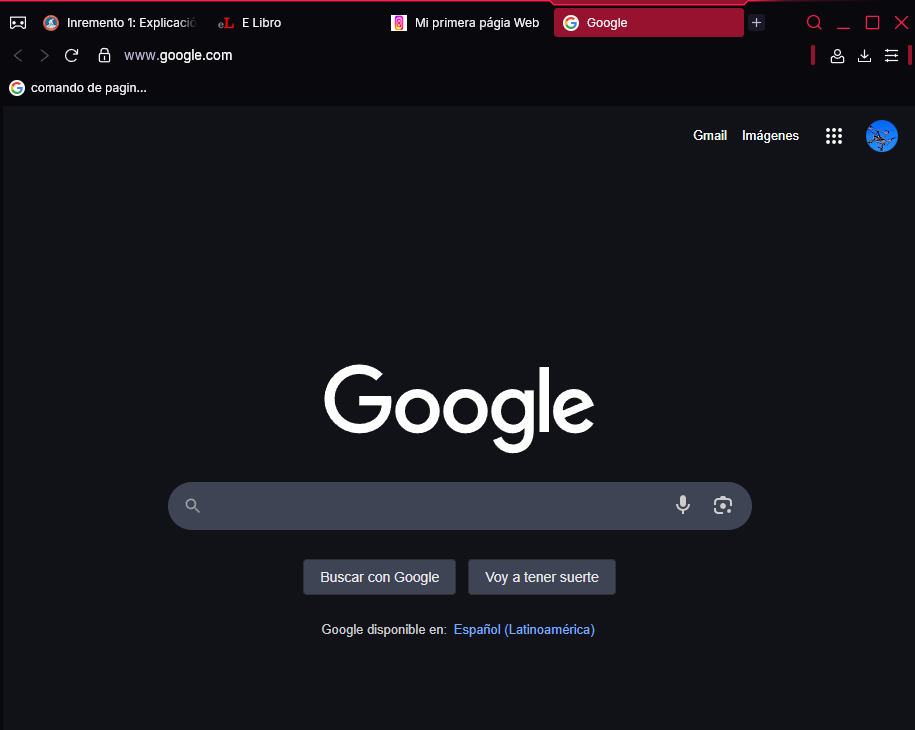
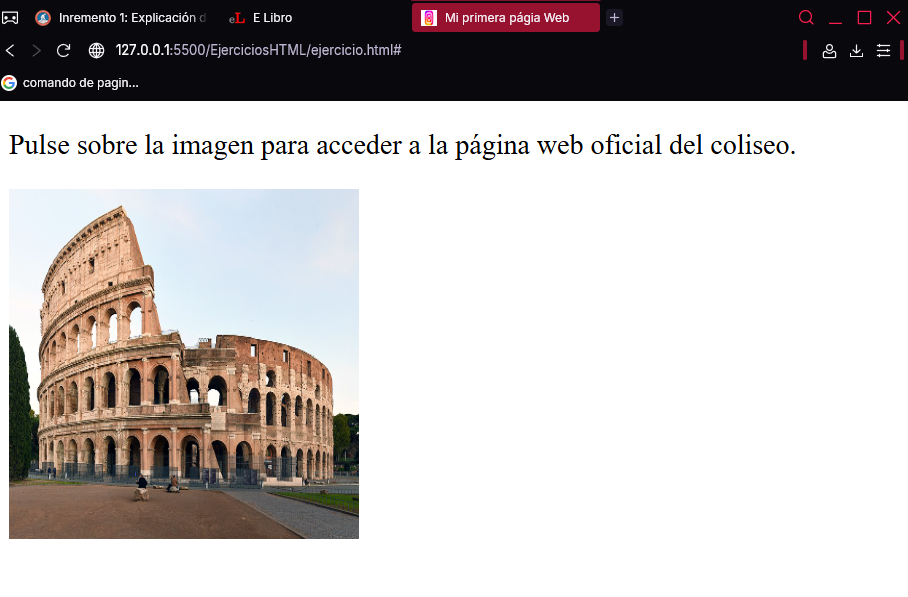
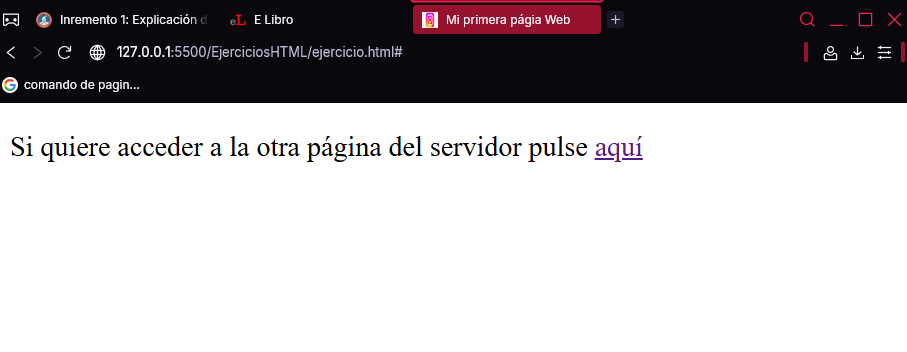 Todavía no pulse sobre la palabra “aquí”, ya que antes tendrá que crear la página a la que se accede desde el hipervínculo que tiene asociado. Su código es el siguiente:
Todavía no pulse sobre la palabra “aquí”, ya que antes tendrá que crear la página a la que se accede desde el hipervínculo que tiene asociado. Su código es el siguiente: 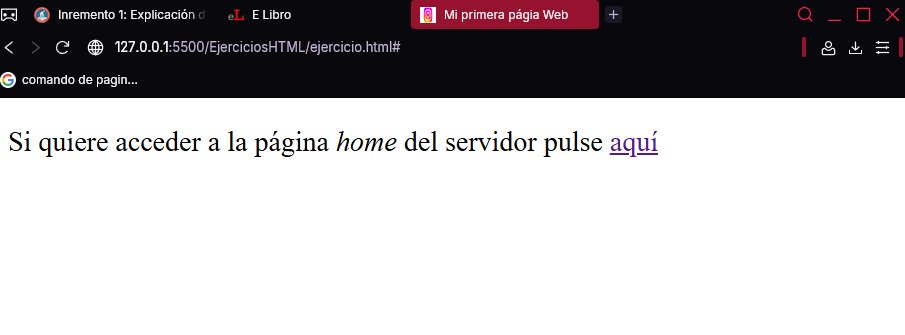 Ahora, al pulsar sobre el enlace “aquí” de esta nueva página volvería de nuevo a la página home.
Ahora, al pulsar sobre el enlace “aquí” de esta nueva página volvería de nuevo a la página home. 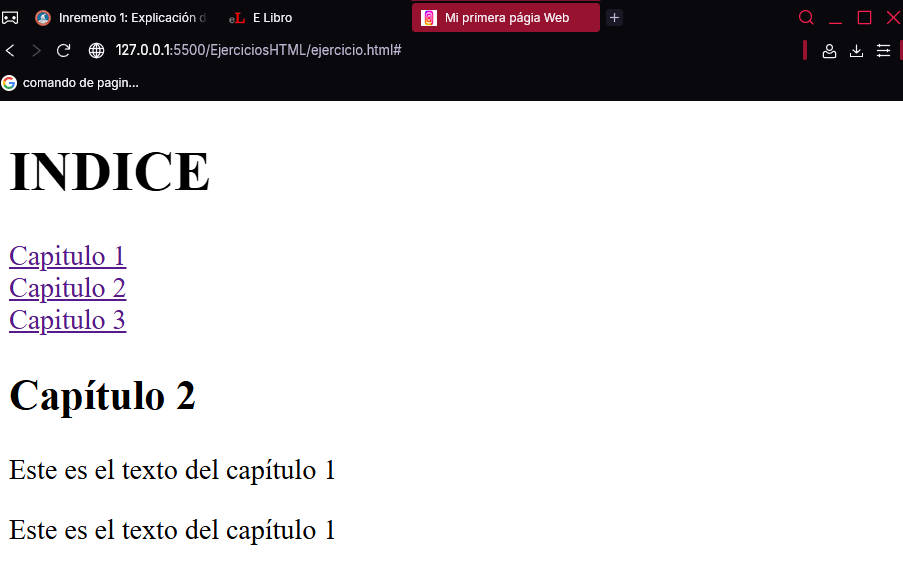
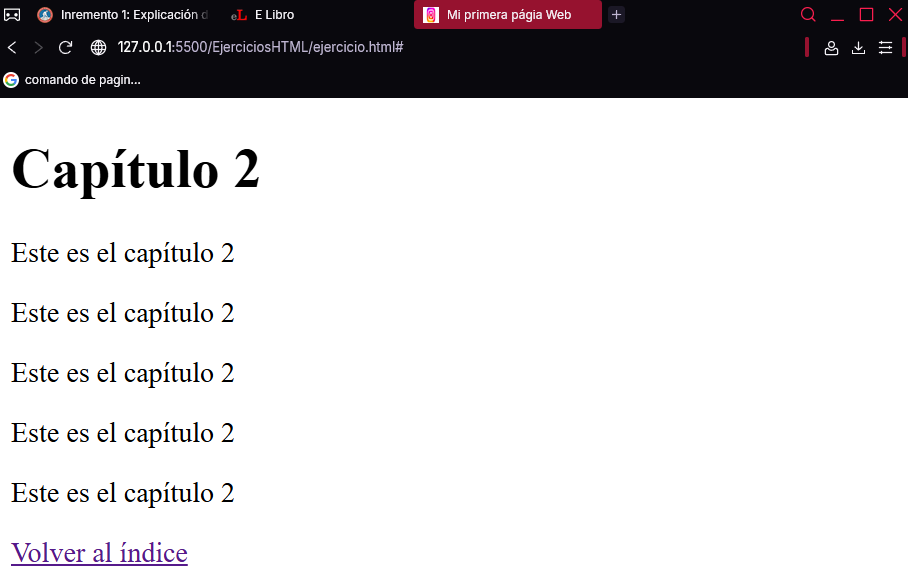 Observe que en la pestaña donde se muestra la página, además del nombre del archivo HTML (o título, si se hubiera indicado en la cabecera) aparece el identificador de la sección a la que se ha accedido, precedido del carácter almohadilla (“#”).
Observe que en la pestaña donde se muestra la página, además del nombre del archivo HTML (o título, si se hubiera indicado en la cabecera) aparece el identificador de la sección a la que se ha accedido, precedido del carácter almohadilla (“#”). 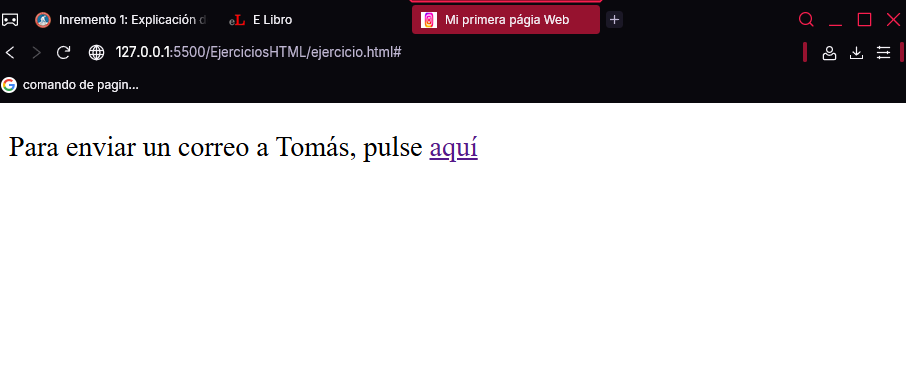
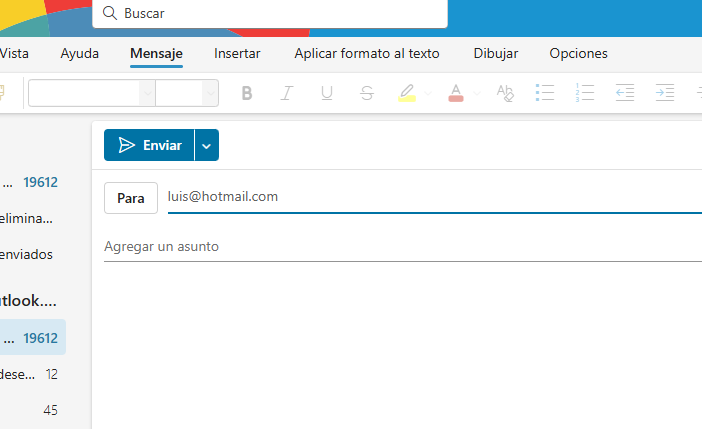
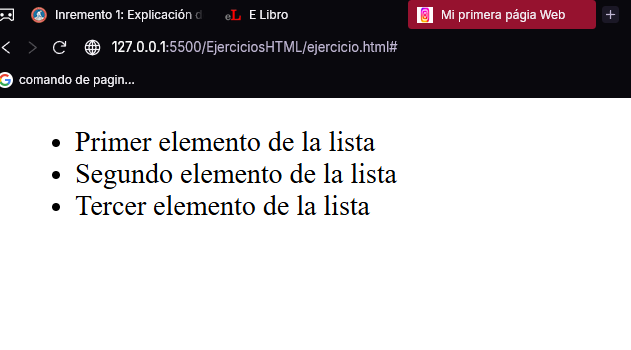

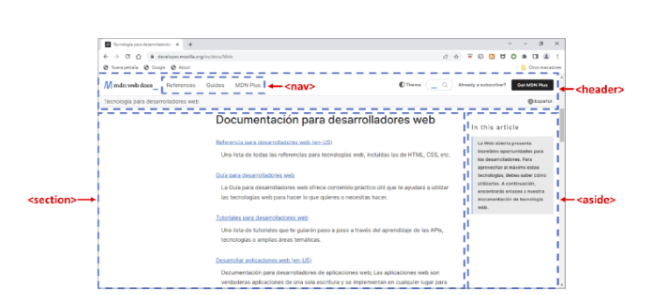 Observe como se funde la barra de navegación y la cabecera en la parte superior. Haciendo scroll hacia abajo, verá la información del pie de página.
Observe como se funde la barra de navegación y la cabecera en la parte superior. Haciendo scroll hacia abajo, verá la información del pie de página.